Ytt试用
jsonnet最大的问题其实是:它支持的是json,而不是yaml. 其实这也不是什么问题,因为yaml是json的超集,json本身就是一个合法的yaml. 但是写起来需要将原来的yaml转成jsonnet,输出成yaml就更麻烦,需要在外围加上std.YamlManifest(),这种侵入式的设计感觉很蛋疼。
yaml本身也有对应的DSL,ytt就是其中一种。蚂蚁开源的kcl也默认输出的是yaml,不过它和ytt的区别是后者本身是合法的yaml,这里先看一下ytt,再看kcl.
安装
很意外,虽然是go写的,但是并不支持go install,需要使用脚本安装:
| |
安装需要翻墙…所以如果是给别人用,最好还是download下来传到oss之类的地方。
设计
ytt的设计思路和jsonnet还是有一些差别的。他是通过在yaml里面注入注释的方式进行扩展:
| |
并将yaml分为以下几类:
- 值文档。类似helm的
values.yaml,其实就是外层的配置;以#@data/values开头; - 值模板文档。用来声明值文档中可用的变量和默认值之类的;以
#@data/values-schema开头; - 纯粹的yaml:不含
#@之类的ytt注释; - 模板:含有ytt注释的yml;
- 覆盖文档:含有
#@overlay/match注释的文档;
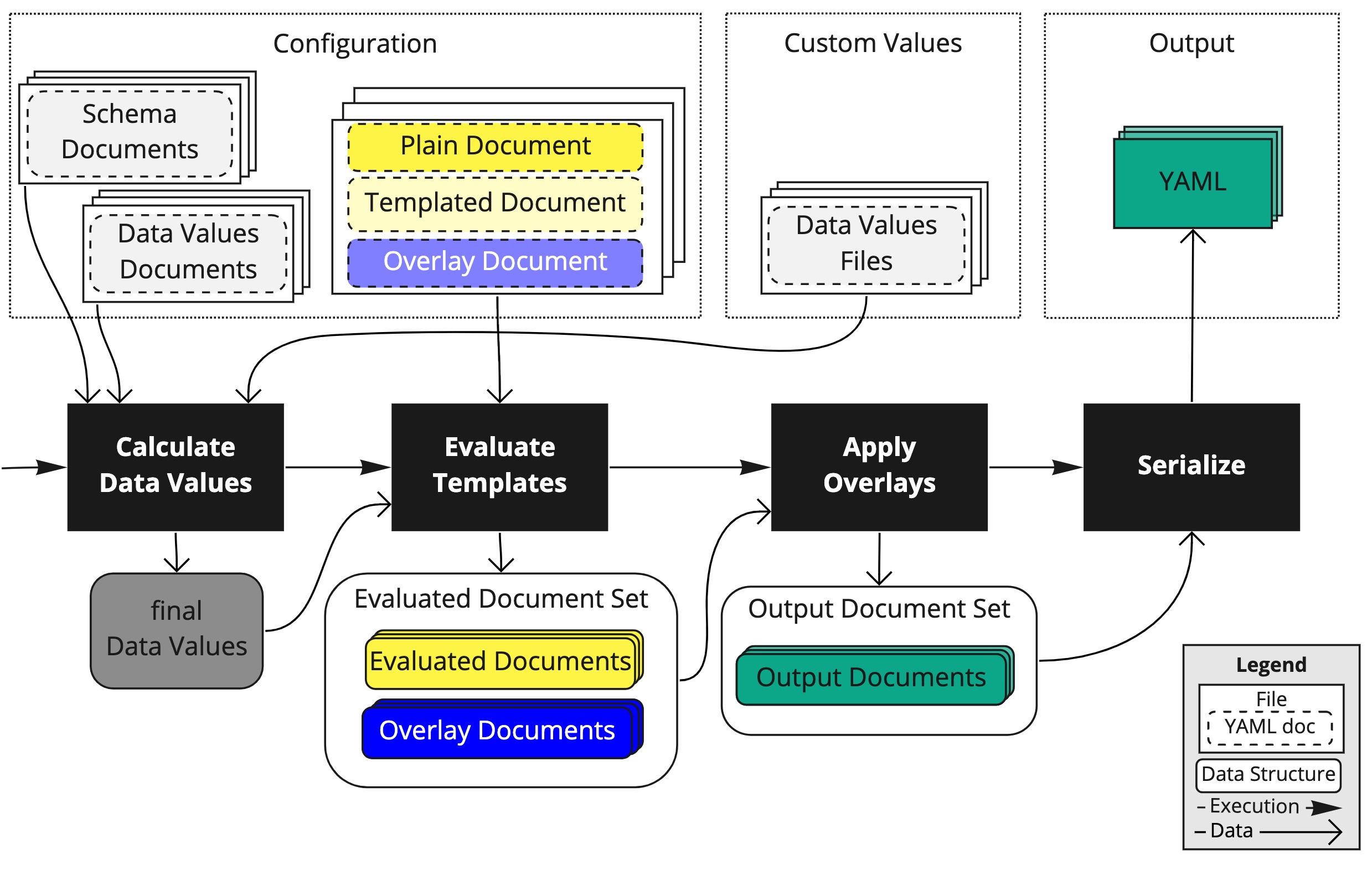
生成yaml的流水线参考上面的图。
语法
使用的是一门叫StarLark的语言,类似Python.
函数包括两种:
| |
这种有return,还有一种或者类似jsonnet:
| |
可以将这两种函数分别放到后缀为.star和.lib.yml的文件里。这种情况下,前者不需要再添加#@前缀。
在模板文件里面通过#@ load("format.star", "fmt")这种方式进行加载。
使用方法
最简单的使用方法,用值yaml渲染模板yaml:
ytt -f schema.yml -f config.yml --data-values-file values.yml
其中schema.yml是用来定义values.yml的默认值和格式、约束的;
values.yml是不同环境的真正需要配置的东西;
config.yml则是生成最终配置需要的模板;
schema语法
大体格式如下:
| |
这里使用类型推断来声明字段类型,同时声明了默认值。有个特例:数组的默认值无法这样声明,数组总是默认为空,需要通过注释来声明默认值:
| |
如果array是一个复杂的object,则可以:
| |
默认情况下字段都不允许为null,如果计算出来的结果是null,则key直接忽略。但是可以通过@schema/nullable设置允许且默认为null. 同样也可以使用#@schema/validation not_null=True显示声明一个字段不能为null, 虽然没啥必要。
特别地,如果一个字段的类型是不固定的(如k8s中的int_or_string设计),可以使用any类型:#@schema/type any=True. 如果是动态的json片段(类似java中的JsonNode或者Go中的RawMessage),也可以用any类型。
类似jsr303中的其他约束,这里也有对应的yaml注释,以#@schema/validation开头,参考这里。复杂规则甚至支持lambda表达式和starlark函数(返回True或者False)。后者被放在后缀为.star的文件里,然后通过#@load("rules.star", "your_function")加载。
data语法
schema是预定义的数据结构,给予约束。如果想要填充数据,使用的是data-value文件:
| |
通过data.values可以引用真正的值的所有字段。
真正的值就是一个普通的yaml文件(plain yaml):
| |
使用的时候:
| |
所以需要3个文件:
- 数据结构定义:schema.yaml
- 填充数据: config.yaml
- 真实数据:value.yaml
其中真实数据还可以通过环境变量等其他方式传入,参考这里,它有一套复杂的数据合并规则。
overlay语法
除了模板渲染之外,ytt还支持类似kustomize的overlay设计:
| |
假设config.yml为:
| |
那么上面的overlay的意思就是:遍历所有yaml,将下面一段yaml patch到源文档。
这里的设计也蛮复杂的,类似git merge,需要考虑各种冲突问题,也可以移除字段等,具体参考这里。
小结
个人感觉ytt设计的不好,一个是写起来很麻烦,全靠注释,官方也没提供ide插件来辅助编码,很容易写错。
另外一个就是硬编码的东西有点太多了,记不住。很多规则也设计的过于复杂了,失去了简洁的特性。
不过最大的好处就是:本质上是yaml基础上的patch,它仍然坚持了jsonnet的设计理念:扩展配置原有语法,这点和kcl的设计思路从根本上不同。