Elastic Observability系统搭建
随着ES v8.4的发布,es对于可观测性三支柱(Metric/Trace/Log)都具有较为完备的支持,Alert功能也能满足一般需求,kibana的看板功能经过这么多年的迭代,可用性也比较好了。最重要的是,兼容OpenTelemetry的标准也保证如果用的不爽也可以用其他开源组件替换,所以项目组目前搭建监控平台,经过评估还是决定优先用这一套。
这里更新为docker安装方式,使用的版本是8.13.
ElasticSearch部分
第一个节点
首先需要优化内核,修改/etc/sysctl.conf,如下:
| |
运行sysctl -p应用配置。
在宿主机的挂载卷下,找一个文件夹用来存放数据,假设为/data/elasticsearch,放入以下脚本:
| |
其中crack.jar对应的是白金版破解,参考这里。注意修改network.publish_host为当前节点的内网ip地址。
运行结束之后,当前目录下会生成password.txt,这里面是供kibana和其他node加入需要的token信息,内容参考如下:
| |
上面<>里面就是自动生成的核心信息,其他节点需要使用的token是最后一个<>内的,30分钟有效。如果超时未使用也可以使用
| |
重新生成。最后的node也可以换成kibana,重新生成上面第3个关键信息给kibana使用。
最后要注意的是上面限制了内存4GB,可以根据机器配置调整该数值,但是不要超过32GB.
其他节点
第一个节点建立之后,其他节点使用token即可加入。不过受限依然需要优化内核,方法同第一个节点,不再赘述。
其他节点的启动脚本如下:
| |
将上面的token换成真实token即可。
第二次启动
除了第一个节点外,其他容器节点无法重启。这是因为ES设计的有问题,ENROLLMENT_TOKEN只能在第一次启动时作为参数。
第二次启动时,在第一个节点宿主机上使用docker cp elastic1:/usr/share/elasticsearch/config . 将配置文件复制出来。
将配置文件传到其他节点,放置在data同目录下,修改config/elasticsearch.yml中的内容,删除或者注释掉cluster.initial_master_nodes所在行。
使用如下脚本启动:
| |
注意这里删除了ENROLLMENT_TOKEN的环境变量,增加了discovery.seed_hosts,对应的值是集群所有节点的ip。
之后再重启,就没有问题了。
理论上也可以直接使用这个方案加入节点,而不使用ENROLLMENT_TOKEN,不过没有尝试过。
注意事项
- 如果要重置密码,可以使用
elasticsearch-reset-password工具。 - 可以通过增加环境变量修改
elasticsearch.yml中的配置,方法是将所有字母变成大写,.变为_,_变成__,如:k1.k2.k_3对应的环境变量就是:K1_K2_K__3,和emqx的环境变量配置方式比较像。 - 如果要重置密码,可以使用
elasticsearch-reset-password工具。
Kibana部分
kibana的启动方式类似加入集群的节点,但是有一些需要额外设置的环境变量:
| |
SERVER_PUBLICBASE_URL根据服务器外网连接进行配置;key1/2/3可以使用随机密码生成器生成32位数字和小写字母混合的随机值。
如果是从以前的kibana进行迁移,这几个key必须和以前一致,否则导出的数据无法导入。
用浏览器打开配置的baseurl,填入kibana对应的token即可配置完毕,后面的配置密码可以通过docker logs kibana看到,最后使用elastic账户密码登录即完成安装。
生成的配置文件在config文件夹里,有需要可以修改。
Fleet Server
Fleet Server是接受Elastic Agent或者各种Beat发送过来的数据并存储到ES的服务。比较蛋疼的是,FleetServer是集成在ElasticAgent这个二进制文件里面的,所以agent体积巨大。
MetricBeats等beats工具则比较轻量一些,可以直接传输数据到ES,不过此类工具就无法通过kibana直接进行配置升级等管理了。
这里还是先使用Agent+Fleet的方式安装,方便后续升级管理。在kibana的Management-Fleet页面上点击“添加Fleet服务器”即可添加代理服务。
在此之前需要准备fleet-server通信用的HTTPS证书(如果全部是内网监控,也可以使用–insecure参数跳过TLS认证,这样就没必要安装证书了)。
进入es节点的docker容器内,依次输入下面的命令:
| |
上面的ip地址需要替换成fleet-server的地址,如果是允许公网访问的,最好把公网ip也加进去。
将ca文件夹中的ca.crt文件和fleet-server.crt、fleet-server.key放到一个文件夹下,假设为/data/iot/fleet。
回到安装流程,点击advanced,选择第2步创建的策略,部署模式选择生产,主机选择在第1步中创建的那个。然后选择主机平台,将对应的cli语句copy下来,并修改<>里的内容,最后的形式大概如下:
| |
如果在FleetServer前面挂了一个负载均衡的反代,那--url后面就要改成反向代理的地址了,实际上es的地址也可以改成反代的地址。
如果需要卸载Fleet(或者说Elastic Agent),可以在kibana界面上操作。
Elastic Agent
由于FleetServer和ElasticAgent实际上是同一个二进制文件,所在FleetServer所在的机器就没必要再装agent了。这里另外找一台主机来安装agent.
代理策略
切换到代理策略页面,先创建一个代理策略。注意默认情况下,fleet和es的地址都是内网的,可以在设置页面里面分别增加一个外网入口,供远程监控时使用:

然后在创建代理策略时,滚动到下面,可以选择外网接入:

特别注意:
默认生成的证书只适用于内网通信,如果要外网通信,CA证书需要留空,且需要在高级配置部分增加:
| |
关闭ssl校验,否则无法正常通信。
如果新建的代理策略和之前的配置非常类似,则可以直接复制原来的策略避免重复配置。
非k8s环境
0. 【可选】登陆要安装agent的机器,先配置ca证书(适用于centos):
| |
- 切到代理策略页面,点击添加代理,选择在Fleet中注册,然后copy下面生成的命令行代码,到要监控的机器上执行;也可以跳过上面的证书安装,在尾部添加
--insecure参数。 - 如果Fleet有多个Server,且没有使用反向代理,这里会默认使用第一个的地址,可以手动修改一下再执行;
- 一切正常的话,主机就会显示在代理页面上;
k8s环境
点击添加代理,选择Kubernetes环境,会下载到一个yaml文件。
里面namespace可以随意更换,挂载的卷也可以根据需求增减,需要注意两个环境变量:
| |
这样设置之后无须在k8s每台机器上安装fleet的ca证书,内网使用的时候可以简化配置,外网的话为了数据安全可以装上。
数据生命周期管理(ILM)
在Stack Management-索引生命周期管理里管理index的生命周期策略,这里默认就会有filebeat和metricbeat自动创建index的生命周期,可以根据需求进行修改。冷阶段不支持搜索,除非有企业许可证。
Elastic Agent采集的Metric,则是默认使用metrics策略管理,即所有数据都在hot阶段,这里可以自定义存储策略。
进入索引管理-数据流,搜索prometheus可以看到metrics-prometheus.collector-test,点击可以看到索引模板是metrics-prometheus.collector。到索引模板里clone这个模板,将优先级改到250(或者直接改这个索引模板的配置也可以),在索引配置页面加上:
| |
点击保存。回到数据流tab,再次点击刚才的数据流,就会发现索引模板已经变成新的了,而且生命周期策略也改成metricbeat了。
实际上,也可以直接修改metrics以及logs的策略,虽然kibana会提示你最好不要修改,但是实际上是可以修改的。
Prometheus Metrics采集
进入Fleet,选择代理策略,选择添加集成,搜索Prometheus Metrics,点击添加Prometheus Metrics按钮即可一键部署。
注意点击修改默认值,去修改服务的地址。
在discover那边,将索引切换到metrics-*,搜索prometheus*:*应该可以看到有数据采集过来。
如果是在k8s里面监控,则比较复杂。首先k8s里面必须安装kube-state-metric,否则无法正常采集pod数据。
如果pod的数量只有1个,可以通过service直接访问,比如iot-iotwebgateway.prod.svc.cluster.local,但是多余1个pod就不行了,此时需要使用autodiscover功能,如下图:

condition里面通过label筛选满足条件的pod,hosts使用对应的变量访问。
黑盒(Blackbox)监控
在Observability-Synthetics-Monitor里有个入口可以配置黑盒探测来监控接口或者主机的可用性,支持进行模拟浏览器/HTTP/TCP/ICMP的探测。
端到端的监测一般还是挺重要的,配置方法也比较简单。
先点击右上角的设置,到位置这里配置探测客户端所在的机器。
然后点击创建监测,选择合适的探测方式(一般用HTTP Ping或者TCP Ping即可)。
然后点击右上角的告警与规则,可以创建统一的告警。
应用日志采集
在Fleet中集成Custom Logs,配置上日志路径就OK了,但是还需要做一些额外的设置。
命名空间
展开高级设置,命名空间默认继承父级(也就是代理策略的),但是也可以修改。比如如果测试环境和开发环境混部在同一台机器上,就需要手动修改了。
数据集
Dataset name非常重要,理论上格式相同的一类日志使用同一个数据集,这样他们会自动重用同一套数据处理和数据映射,比如java的日志可以都叫java_iot,需要注意的是名字里不能有"-"。
如果采用上面的命名,且命名空间为dev,则对应的数据流即为logs-java_iot-dev,可以在discover中建立对应的视图。
多行日志捕捉
java的堆栈往往是多行日志,需要在Custom configurations里面额外增加一些配置,例如:
| |
其中:
pattern:正则表达式
negate:正则表达式是否正向生效。 true:符合正则表达式的为一个基准行, false:不符合表达式的为一个基准行。
match:基准行和后面after或前面before划分为一组。
我们的日志一般是日期开头,可以用上面的配置进行捕捉。
到这里,可以先点保存,看日志能不能正常采集上来。如果你需要对日志进行一些处理再入库,可以看下面的采集管道配置。
采集管道
默认日志采集后都在message字段,一般我们需要进行一些预处理再入库,比如将log.level提取出来成为单独的字段等。
在采集管道处点击“定制采集管道”,会自动新增一个名为**logs-{dataset}@custom**的管道,后面所有同名数据集都会自动应用这个pipeline。
实际上你自己按着这个命名规则创建pipeline也行,会自动应用到对应的dataset的。如果dataset为java_iot,手动创建一个logs-java_iot@custom的采集管道就行。
下面开始配置:
对于plain text日志,最常用的processor是dissect(中文翻译是分解),grok和script三种,用来提取字段,其中grok用的其实就是正则匹配。
假设我们这里有golang服务日志格式如下:
2022-08-18T15:54:52.866+0800 WARN internal/kafka.go:37 [kafka]poll errors:[{ 0 client closed}]
这里有文件路径,但这个字段只有debug模式下才打开,正常的日志格式则是这样的:
2022-08-18T15:54:52.866+0800 WARN [kafka]poll errors:[{ 0 client closed}]
由于字段不固定,所以这个需求无法使用dissect完成,只能选择grok或者脚本。
这里用grok,参考官方文档,可以写下如下匹配规则:
%{TIMESTAMP_ISO8601:@timestamp}%{SPACE}%{LOGLEVEL:log.level}%{SPACE}%{GREEDYDATA:message}
先到kibana开发工具下面的Grok Debugger里面去测试,可以看到模拟结果为:
| |
如果我们不想要中间的internal/kafka.go:37这部分,就稍微麻烦一些,定义
CALLER (\s+([/\w_%!$@:.,+~-]+|\.)*:\d+)?
然后将表达式改为:
%{TIMESTAMP_ISO8601:@timestamp}%{SPACE}%{LOGLEVEL:log.level}%{CALLER}%{SPACE}%{GREEDYDATA:message}
这样就可以强行把中间的caller部分过滤掉。
需要注意的是,在kibana界面上添加管道时,需要对\进行转义,即改为(\\s+([/\\w_%!$@:.,+~-]+|\\.)*:\\d+)?。
添加完成之后可以点击添加文档,在pipeline里再测试一次。同时也可以在后面添加别的pipeline进一步处理,比如添加新字段等。该功能的详细使用步骤可以参考这里。
java错误日志的捕捉可以使用这个表达式:
| |
在下面的模式定义里面增加:
| |
这个自定义的正则会捕获多行message直到消息的结束。
特别需要注意的是,@timestamp必须转为正确的日期格式,对于java而言就是yyyy-MM-dd HH:mm:ss,SSS,还需要正确设置时区,如下图:

部分预处理需要使用painless脚本,比如某些服务没有区分error日志与普通日志,那么需要drop掉warn等级以下的日志,可以用ctx.log.level != 'WARN' && ctx.log.level != 'ERROR'。
一般同一种语言使用相同的日志格式,这里假设添加管道的名字为golang-common-log-parser,并创建一个common-logs-policy的策略,对所有应用日志生命周期进行统一管理。
NOTE: 建议加一个处理失败则drop的处理器,避免部分数据格式问题导致的发送失败。
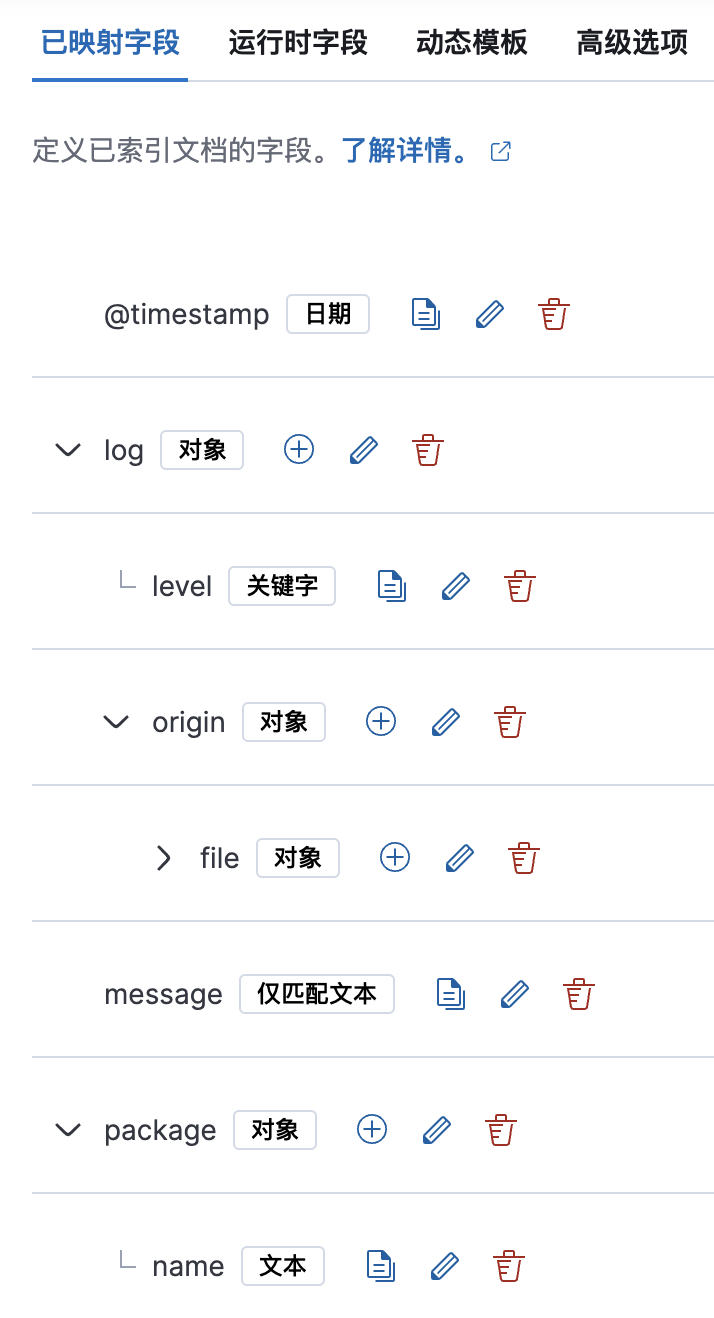
字段映射
保存上面的pipeline,会自动回到Custom Logs的设置页面,下面需要对刚才通过pipeline增加的字段做类型定义,点击映射下面的“添加定制映射”,会自动创建一个和定制采集管道同名的组件模版。
下面主要配置字段映射:
java的可以参考下面的字段配置,其他语言类似。
然后一路点下一步,保存,创建完毕。
可以去索引模版里检索dataset复核一下。
另外提一下,golang的panic日志一般不需要采集,直接用File Integrity Monitoring Integration这个集成进行文件监测即可。
调试
如果一切顺利,至此你应该能在discover里面看到处理好的日志了。
如果很不幸没有任何日志,一般都是你的pipeline有问题。可以先clone pipeline做个备份,然后把pipeline删了,看日志能不能正常上来。
如果肉眼调试pipeline太困难,可以进入fleet,点击主机名,点击日志,将页面滚动到最下方,有个代理日志等级调节的下拉框,改成debug,点应用配置。
这样filebeat会打印出来到底为啥上传失败。
迁移pipeline
如果你需要将迁移kibana的配置,仅仅使用"已保存的对象"进行导出是不够的,pipeline和模板都不会迁移。
pipeline可以到详情页右下角,点击“显示请求”,然后到控制台上运行命令。
KQL简单学习
ES的查询语法是复杂的JSON,直接在界面上不方便使用,所以kibana实际上使用了一种名为KQL的方言(DSL)。其使用较为简单,这里记录一下要点:
- 简单的term匹配,使用
k: v的形式,多个v可以用空格隔开,表示或关系。如果值中包含空格,使用双引号; - 允许使用and, or和not逻辑操作,允许使用括号;注意not是放在k前面的,而不是v前面;
- 数组匹配多个值,使用and,如
tags:(success and info and security); - 范围查询,支持>, <, = 各种组合;
- 日期查询一般用右侧的time filter,不过也可以手动写
@timestamp < "2022-10-10"之类的,也支持类似influxdb的算术表达式; - 允许使用
*做模糊匹配,k或者v中都可以; - list of object的匹配,匹配object中的字段,使用大括号。例如
items:{name: banana}这种; - 如果是多级嵌套,如
k1:[{k2: [{"k3": "v"}]],搜索的时候需要写全路径,即k1.k2:{k3: v}这种搜索;
安装Elastic APM
这里的APM其实指的是Trace系统,通过Fleet直接绑定集成就可以。需要注意apm采集会影响应用程序的性能,如果部署规模不是很大,不太建议集成。
推荐使用OpenTelemetry的Agent进行Export,方便将来迁移到其他平台。
对于Java而言,可以使用自动导出,支持大部分组件。Go/C++服务则需要手动集成,并且需要修改大量代码。
跨服务传递时,一般通过traceparent和tracestateheader进行传递,相关w3c标准见这里.
sdk提供了propagate相关的API,用来Inject和Extract trace上下文,使用起来非常方便。
周期性任务
很多指标需要持续计算,比如日活,统计周期内的错误占比等。
在StackManagement-汇总/打包作业里,可以创建定时任务,具体使用请查看官方文档.
告警配置
下面开始配置告警,告警有很多入口,请根据需要选择:
- 在可观测性(Observability)里,这里可以设置简单的阈值告警;
- 在Security-告警里,这里可以使用复杂的表达式从ES中进行各种数据查询并创建告警;
- 在Stack Management-告警和洞见-Watcher里,这里可以直接用json语句创建告警,这是最灵活,同时也是最复杂的方法;
- (推荐)还是在告警与洞见这里,在规则和连接器里,这里可以设置所有场景的告警,也包括一般的es查询;
连接器
告警的发布对象被称为“连接器”,免费提供的只有kibana日志和写入es index,有三个解决方案:
- 可以自己写一个简单的工具监控es/kibana日志并调用钉钉发送告警;
- 使用ElasticAlert2项目;
- 升级到白金许可证(或者使用这个项目);
这里假设你已经获得了白金许可证,下面使用webhook报警即可。
首先在钉钉群里配置一个机器人,点击群设置-智能群助手,添加一个webhook机器人,建议打开IP白名单,或者告警关键词。
钉钉创建一个含有access_token的URL,copy下来,在webhook连接器POSt后面paste这个地址,然后添加headerContent-Type: application/json,用json格式发送。
点击保存,在测试页面进行报警测试,消息的格式请参考这里,可以用
| |
做个简单测试。
告警规则
在安全里可以安装Elastic预构建的几百个规则,不过不是很建议全部导入,因为大部分都没啥用。可以考虑激活k8s,linux之内tag的规则,如果使用云厂商自带的监控,则一般不必再使用这里的告警功能,相当于重复监测了,而且有性能损耗。
Observability使用示例
如果只是简单的创建一个error日志告警,可以在Observability点击创建规则,选择日志阈值,然后创建一个如下的规则:

由于我们在上面的数据预处理里面已经将log.level映射出来,所以这里使用这个字段判断一下就行。连接器选择刚才创建的webhook,在Fired和Recovered两种条件下创建两个不同的告警提示即可。

右侧可以看到这里可以使用的变量。可以注意到这里并没有字段可以拿到日志的详情,这是因为这里只能做聚合查询,肯定是拿不到具体日志的详情的,不过可以通过group by source.ip之类的方式获取到具体的主机。如果需要直接提示详细的错误,需要用其他方案;
告警与洞见使用示例(推荐)
点击创建规则,选择Elasticsearch查询,选择KQL查询,创建一个视图logs-golang*作为索引,这样就自动匹配所有golang服务。
如果不想这么粗放的创建告警,也可以用logs-golang_sip_server*,作为匹配,这样就匹配到单个服务的所有日志。所以index的名字很重要,不要随便取。

查询条件仍然是日志等级为ERROR(这里是区分大小写的,可以在预处理里统一转换成大写),这里就是过去5分钟出现任意错误日志则触发。这里在body里面可以拿到{{context.hits}},我们可以通过mustache这个模板语言对其内容进行解析。
告警模板:
| |
这里三个双引号是kibana特有的语法(与json实际上不兼容),方便写多行字符串。
恢复模板:
| |
效果如图:

安全告警使用示例
这里不太建议使用,非安全问题用这里的规则不太符合ES本身的设计,具体使用方法请自己摸索。
watcher使用示例
watcher属于高级用法,需要自己写全量的JSON来拼凑出表达式,而且也不支持使用已经配置的连接器,有兴趣可以看这里,官方github给出了大量examples,以供参考。这里不太建议使用,因为用起来很麻烦,也不好调试。
ElasticStack自身的告警
在告警与洞见里,默认就有一些检测ES本身状态的规则,可以修改。默认只是将告警输出到kibana日志。
查看日志级别,如果是Warning以上的,可以加一个钉钉通知:
| |
基础设施告警
点击创建告警,在Metrics中点击库存(这里翻译也不对……),这里可以对一般指标(cpu、内存等创建告警)。通用告警模板:
| |
其他的指标都在custom metric选项里,如磁盘空间使用,可以用system.filesystem.used.pct. 建议根据自己的需求阅读官方文档中system和linux这两个采集模块的相关字段解释。
ES Monitor监控周期
如果使用metricbeat来监控es/kibana,可以使用ILM控制存储周期,但是如果用es自带的监控,必须要手动修改存储周期,方法是在控制台里面输入:
| |
这里将周期改为3天减少日志存储消耗。
新版本可以通过elastic agent监控es了,只是界面上没有提示。
看板配置
在kibana的Analytics部分,可以创建各种看板。
Dashboard里面内置了一部分仪表盘,也可以自己使用KQL筛选数据后自行创建,一般内部监控用这个创建可视化就够了。
Canvas部分则可以通过灵活地拖曳完成各种图表的数据、样式配置,可以非常方便地作出各种炫酷的大屏。
由于这部分内容比较符合使用者的直觉,且更偏向于前端的工作,这里就不写详细的配置步骤了。有需求可以阅读kibana的文档来学习。
附录1:中间件采集
大部分中间件都集成在fleet里了,如果不能满足需求,可以点开custom这一栏。已经有官方集成的这里就不写了,包括MySQL、Redis、kafka、rabbitMQ和Nginx。
Docker
所有通过docker安装的中间件,可以统一使用docker这个集成收集日志,以及内存、cpu、网络等基本指标信息,dashboard那边也会有对应的图。
部分中间件可以通过日志完成所有告警,但是有些指标日志里面没有就要自己想办法。可以根据容器名称或者镜像名称来对特定容器使用的内存、cpu进行告警。
注意:如果容器直接使用了宿主机网络,即–net=host,则无法获取独立的网络使用信息。
emqx
去dashboard-插件里面打开emqx_prometheus,通过localhost:8081/api/v4/emqx_prometheus?type=prometheus即可获取。
不过需要注意的是有时候会有bug,界面上显示启动成功,但是curl提示404,则实际上是启动失败了,可以去容器里面通过emqx_ctl plugins start emqx_prometheus手动启动。
该API不需要密码,每个节点统计是当前节点的数据而不是整个集群的数据。
另外,需要注意的是,fleet的Prometheus插件的query参数是在高级选项里面设置的,不是直接写在url后面的。
如果想要统计整个集群的数据,也可以配合用官方的emqx_exporter,然后去通用-用户里面添加一个用户,然后增加配置文件:
| |
如果是emqx5.x,上面api_key和secret对应的是通用-应用里面自动生成的密码对。
启动命令:
| |
通过curl localhost:8085/metrics即可看到metrics,一个集群有一个exporter就够了。
告警可以考虑加上因为队列满导致drop的消息数,即prometheus.emqx_delivery_dropped_queue_full.counter的值,以及离线客户端占比:prometheus.emqx_client_disconnected.rate.
告警提示1:
| |
告警提示2:
| |
Kafka
kafka可以在启动时将Jolokia jar包注入,作为代理,作为Prometheus的exporter,这样做以后就可以直接用集成里面的kafka采集数据了。
还有个方法是使用独立的lag-exporter,监控消费lag情况,虽然官方已经将该方案的仓库archive了,但是目前还是能用的,以后就不好说了。
参考配置:
| |
建议只关注量数据量比较大的topic,以及相关的消费者,避免采集的数据过多。启动命令:
| |
告警条件:
prometheus.kafka_consumergroup_group_lag.value >= 100
告警提示:
| |
redis
redis主要监控慢日志,慢日志需要在启动redis时配置好,如果没有配置,只能通过命令打开:
| |
第一行的10000表示10毫秒,可以酌情增减,一般不建议超过20毫秒避免阻塞其他命令,第二个表示记录慢查询的长度。
可以通过
| |
获取最近一条慢查询日志。
fleet集成里面有个redis,可以通过info周期性采集数据,根据**redis.info.slow****log.count > 0**发出告警。
influxdb
我们生产中用的是influx-proxy作为负载均衡代理,可以先收集influx-proxy的日志,对error发出告警。
influxdb本身可以使用telegraf作为exporter,参考配置如下:
| |
influxdb默认导出的metrics非常多,这里做了一些过滤。
运行命令:
| |
可以对写入失败数做告警。
日志告警,条件为message里面含有error且container.name: “influx-proxy” :
| |
rabbitmq
SLB对rabbitmq的探测会打出error日志(socket is not connected),这个可以无视,或者让运维配合修改SLB探活方式。
rabbitmq可以使用通用的Prometheus采集器采集,方法如下(3.18+):
进入容器内,使用``rabbitmq-plugins enable rabbitmq_prometheus`打开Prometheus端点开关,默认使用15692端口。如果之前没有导出这个端口,只能删掉容器重新创建了,然后使用curl localhost:15692/metrics获取指标数据。
还有个更简单的方案是直接用15672进行采集,fleet自带了一个rabbitmq的采集器,可以使用那个。
seaweedFS
参考这里,需要启动服务时额外配置metrics端口。
官方给了grafana的json配置,kibana这边就需要自己配置了。
nacos
官方支持Metric导出,参考这里
阿里云商用中间件
可以参考aliyun-exporter这个repo,虽然已经archive,不过思路没变。
附录2:ES常见问题
磁盘空间不足
到Stack Management-索引管理里,打开包括隐藏的索引,点击存储大小,使其从大到小排序。
点击索引名称,右侧会显示“索引生命周期管理”,查看对应的生命周期策略是否需要调整。如果是托管的策略,不建议直接修改,改为修改索引/数据流对应的模板,在模板中添加生命周期策略即可。
可以视具体情况删除部分索引。
索引无法删除,提示bad request
这种一般是由于索引正在被使用,必须先解除使用。
点击索引名称,点击“编辑设置”。
先看索引是否设置了index.lifecycle.indexing_complete=true,有的话改为false,这个选项会导致索引skip rollover,一直往同一个索引里面写。
然后为索引正常设置生命周期策略(如:"index.lifecycle.name": "metricbeat"),并确认有个别名:index.lifecycle.rollover_alias,别名可以随意。
最后需要手动滚动数据流,到控制台上运行:
| |
正常的话,会创建一个新的索引。这样就可以删掉原来的索引了。
字段类型冲突
如果你在discover中看消息时看到字段类型前面有个感叹号,一般是改了字段映射导致的,没什么影响。如果想修正这个问题,需要到Stack Management-数据视图里面查看具体冲突的原因。
一般删掉旧的索引就可以了。
但是有些情况属于是处理不当导致的,例如采集管道里同一个字段,有时候是字符串,有时候是object,这种一定会冲突,但是一般不影响使用。
同一个数据集,但是新增命名空间无日志
比如测试环境正常收集数据,但是到生产环境就没数据了。首先check一下日志的格式是不是变了,pipeline那里可能对不上。
此外,这可能是由于索引模板禁用了自动创建索引导致的,需要去索引模板那边打开自动创建索引。