Apache Nifi使用笔记
基本概念
虽然Nifi支持二进制数据(如视频流),但是我们一般还是拿来做可读数据(类似表)的处理。Nifi将这种数据称为面向记录的数据(record-oriented data),Nifi使用了一种类似XPath/JsonPath的抽象来定位数据,即RecordPath。
首先理解一些基础概念:
- Record: 记录,可以理解为一条数据,对应一个avro Schema(类似json schema);Record是一个抽象的概念,实际使用时需要落地为具体的格式(一般是avro);
- FlowFile: 流文件,一段数据,包括多个Record,以及一组attribute;
- Attribute:属性,流文件关联的一组kv值;如record总量、文件名称等;
使用Nifi做ETL,核心的东西都围绕Record来进行。由于Nifi已经发行了很多版本,为了保持兼容性,很多旧的processor是Record的落地实现(可以理解为接口和实现的关系),一般不用关注。
如果不记得processor的用法,可以在画布上右键组件,view usage查看文档。
一般流程
NIFI没有流程管理的概念,登陆进入主界面就是一个画布。每个ETL流程肯定要先建一个ProcessGroup,类似文件夹的概念;可以按着项目>流程名称这两级分组。页面左下角显示了层级,想要进入进程组,就右键点击后选择enter group(或者双击也行).
一般批量ETL流程是:
GetFile->QueryRecord -> UpdateRecord -> PutRecord
非文件类数据ETL,有一些专用的query方法,比如DBMS一般是ExecuteSQLRecord直接获取Record;Mongo有GetMongoRecord;如果后缀不是Record,一般是返回一个Avro流,后面还是可以跟UpdateRecord,Reader选择AvroSet即可。
基于CDC的ETL流程一般是:
CaptureChangeMySQL -> RouteOnAttribute -> UpdateRecord -> PutRecord
除了MySQL基于binlog的CDC,还支持直接启动HTTP服务接收数据(Listen HTTP)。事实上Nifi做CDC功能很残,窗口、水印之类的常用概念一概没有,一般还是用Flink来做。
Query和Put其实没啥好说的,一般选好对应的source和sink就行,关键是transform.
常用的Transform思路
- 首先在Query的时候就可以做简单的、初步的变换,即Select xxx as xxx这种,同时可以做一些简单的字符串拼接之类的操作;Query使用
Apache Calcite实现,支持ANSI SQL,具体语法可以查询calcite的文档,注意很多Function和MySQL并不一致; - 在UpdateRecord里,通过RecordPath和Expression Language来更新kv值。注意这两个是不能结合使用的,至少到1.14还不可以:
- RPath本身有一些字符串处理的Function,但是不能做复杂计算、条件判断之类的;
- EL可以通过
${field.value}引用值,完成常见Transform,但是只能引用RecordPath指定的值; - 如果想要结合使用,一般需要用两个连续的UpdateRecord。一个简单的例子:需要使用两个字段来做加法,就先用concat把两个字段的值连起来,然后再通过substring取出来做计算;
- 当然这个例子里,在QueryRecord里先用SQL做计算更好,事实上这玩意能用SQL就用SQL,EL不太好用;
- 使用
JoltTransformRecord,这是一种DSL,能够完成简单的数据清洗、计算工作;可以参考这里; - 使用
ScriptedTransformRecord,直接写js/lua/python脚本进行计算,比较灵活,但是性能理论上比其他的要慢一些。不过这个也不一定,对性能敏感的话可以先测试一下再决定用哪个。脚本语言里性能最好的是groovy,当然如果不熟的话用python也是可以的; - 使用非Record类的processor。Nifi里面有针对特定数据格式的其他Transform,比如对Json有jsonPath计算,后者使用updateAttribute配合attributeToJson之类的。不过总体来说,主要使用上面4个processor做数据清洗、转换。
例子
如果源数据是一堆csv文件,没有header,目标是写到MySQL里。
以手头的某项目告警数据抽取到MySQL为例。
源数据是从oracle中抽取的,格式如下:
| |
例子:
132743569098900000,baojing,NULL,1,报警打开尚未确认,TBDD.B15.RQ.O2_LO_WARNING,1,NULL,192,0,3,NULL,NULL,NULL,NULL,燃气舱氧气低报警状态,2021-08-25 09:21:50.000
可以拆分一下方便映射:
| |
目标表:
| |
映射方式:
| 源字段 | 目标字段 | 计算方式 |
|---|---|---|
| id | 源表没有单个的主键,可以用concat( ‘1-0-‘, chrono, ‘-’, name)拼一个出来 | |
| project_id | 写死是1 | |
| sub_project_id | 写死是0,或者没有这个字段也行 | |
| type | 只有氧气(3),温度(1)和液位(24),可以通过Description字符匹配来映射 | |
| AlarmLevel | level | 已有数据里面全部是0 |
| Description | content | |
| AlarmState | is_solved | |
| UserComment | result | |
| TS | start_ts | 需要将北京时间的字符串转成unix时间戳 |
| TS | remote_time | 对方只有一个时间 |
| Name | device_names | |
| Threshold | threshold | |
| NumParam | realtime_value |
没提到的就是没用上,使用默认值即可。
在Nifi中添加processor:
- 首先添加
GetFile,配置文件路径;为了方便测试,我们改为ListFile+FetchFile,这样在文件夹里使用touch更新一下文件创建时间,就可以重新触发抽取; - 添加
QueryRecord,RecordReader选择CSVReader,RecordWriter选择AvroRecordSetWriter; CSVReader里面Schema Access Strategy选择Use 'Schema Text' Property,然后在下面的Schema Text里面填入avro的schema,注意允许为null的,type都要加上null。另外就是需要标记NULL string为NULL。
| |
CSVReader的其他配置一般都保持默认即可,如果数据里面有中文,确认一下csv是不是已经转成了utf8字符集;- 在
QueryRecord里面,添加一个自定义property,假设名字叫extract,内容写SQL语句:
| |
如果mysql的话,其实直接在这里就可以完成所有ETL,但是实际遇到了几个问题,所以必须要在后面追加一个UpdateRecord:
- ansi sql里面,没有什么很好的方法将string转成unix时间戳;配置
\start_ts为${field.value:toDate('yyyy-MM-dd HH:mm:ss.SSS'):toNumber()}进行转换; - 另外就是calcite默认不支持中文,目前没找到设置的办法,配置
\type等于${field.value:contains('氧气'):ifElse(3, ${field.value:contains('温度'):ifElse(1, 24)})}来转换;
- 然后添加一个
PutRecord,将QueryRecord和PutRecord连接起来,关系就是extract; - 配置
PutRecord属性,填入目标数据库表信息;
最后大概样子:
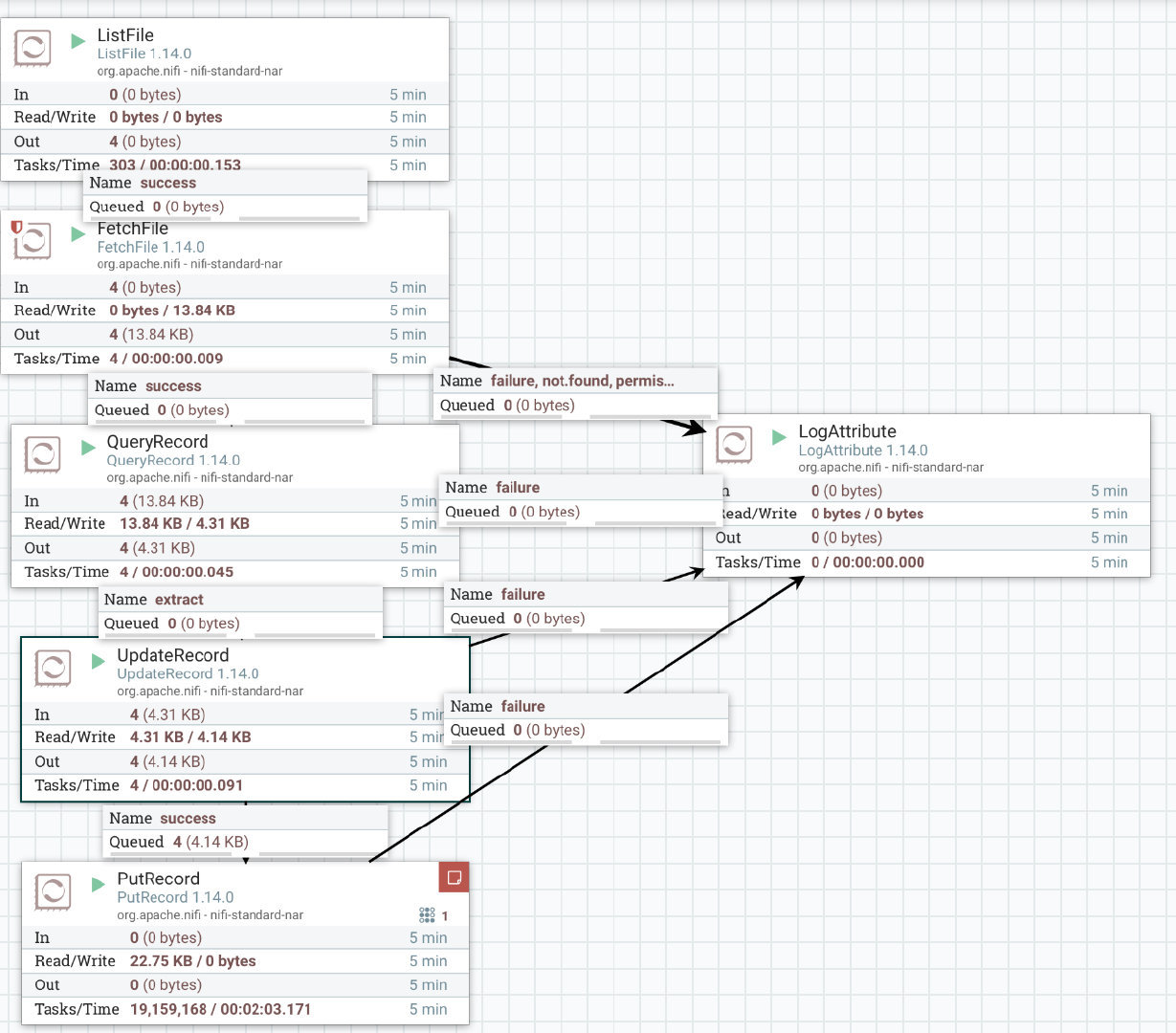
右边的LogAttribute是失败的时候在日志里打印出flowFile属性,方便调试。PutRecord测试的时候还是会报错,因为源表没有主键,不过整个链路还是跑通了。
最后依次启动各个组件,或者点击左侧进程组的启动,进行测试。