边缘应用托管方案设计
需求与现状
我们需要一套方案,来解决边侧应用部署的问题。这不仅仅包括边缘网关,同时还应包括独立部署整个iot平台,以及任意第三方服务。当然,除了部署之外,还有权限隔离、运行监测(可观测性)和远程调试等常见的需求。目前来说,我们不需要考虑边缘端服务器配置轻量化需求,所以后面略去了这部分的考量。
目前,IoT云测服务运行于阿里云托管的k8s中,相关权限在运维手中。跟院里大部分服务一样,IoT整体架构并不强依赖于k8s,而是使用了SpringCloud等框架,换句话来说,并没有云原生化。特别地,视频云服务使用了大量UDP based(RTP/SIP)协议,而k8s对于非TCP based协议的网络支持都比较有限,短时间内恐怕很难on k8s. 所以,我们必须同时支持k8s部署和传统部署。
我们可以强制要求所有的应用运行在容器中,通过合理规划端口使用和卷挂载,理论上可以解决绝大部分服务运行问题。但是第三方应用可能不支持容器化。那么,我们的方案最好的情况需要支持三级部署:裸机、容器化和直接部署在k8s里,次一级也至少支持容器化和k8s两种(因为裸机部署很难做到权限、环境隔离)。当然,即使不支持裸机部署,也要考虑如何满足裸机监控运维的需求。
边侧服务除掉最早期使用windows server的版本,目前都运行在一期基于k3s的应用托管容器中。目前的应用托管(以下简称v1)架构比较简单:
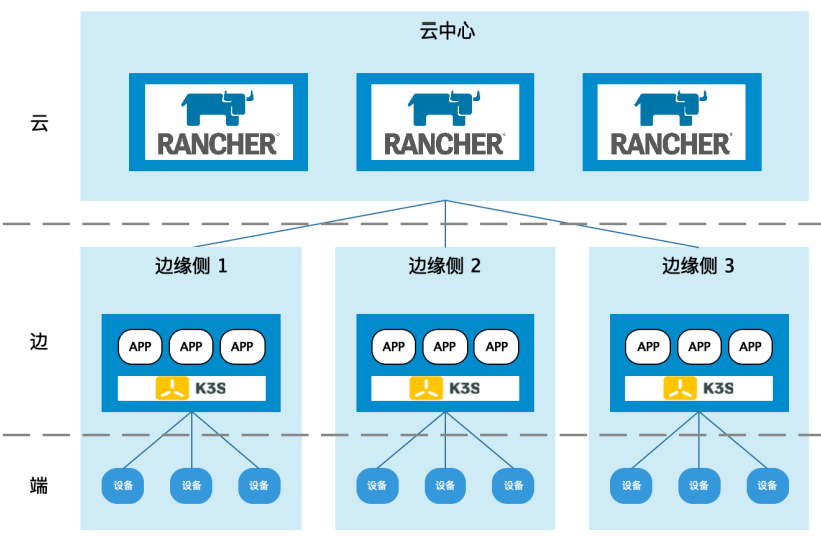
云端是一个rancher集群,边侧就是一个k3s集群(类似于一个k8s集群),云边之间有建立websocket通道,而各边侧之间是相互隔离的(当然可以通过云端rancher中转通信,不过这个不是out-of-box的)。该方案对云端有没有k8s没有需求。
墨斗通过调用rancher的各种API,来与边侧的k3s集群的API Server交互,从而达到远程部署应用的目的。不过rancher v2的API并没有官方文档,需要自己通过web console抓包来确定API。
虽然目前v1版本还做的比较简陋,但是显然该方案可以解决所有服务都能跑在k8s中的需求,只是后续需要开发的东西还欠缺非常多。
统一托管方案
裸机部署
裸机程序部署方案,在k8s甚至docker出现之前就有很多,比如Ansible/Puppet/SaltStack/Chef等。这些方案其实更偏向于服务器管理,即传统运维配置管理工具,对于软件部署其实并没有提供一致的抽象方式。Chef倒是提供了Chef Habitat,用来完成应用打包,但是这实际上没有啥意义,你不能指望使用传统部署的那些供应商提供类似rpm/deb的最终打包。
在这些工具中,hashicorp公司的terranform独树一帜,它提供了类似k8s的配置即基础设施方案,可以理解为通用的编排工具,不过很可惜该工具仅支持云端资源编排(如阿里云)。另外该公司的Nomad是一种不同于k8s的容器编排方案,有兴趣也可以了解一下。
在这一层做应用交付抽象非常困难,所以我们应当简化在这一层的设计,毕竟大部分服务应该还是可以容器化运行的。如果我们只需要一个简单的远程工具,不考虑批量部署之类的功能,那么我们只需要提供一个ssh访问的功能就够了。边缘服务器一般是工作在内网中的(behind NAT),有一些开源项目可以提供类似向日葵的内网穿透功能,比如bore/frp/nps. 他们工作的原理是从内网向公网服务器发起连接,建立tunnel,从而可以将本地端口转发到服务器上,这样就可以通过服务器进行远程ssh/rdp访问了。而一旦有了这个端口,后续就可以使用Ansible这种无Agent配置工具进行批量管理了。
值得注意的是,裸机方案不仅适配于应用托管,在更小型的环境里(如树莓派或者更低的配置)运行应用程序都应当考虑该方案。因为docker启动之后至少需要200~300M内存,k3s更是需求1G内存。此外,虽然很少,但是对于某些强依赖windows环境的应用,也只能采用裸机部署方案。
容器部署
目前流行的开源方案中,portainer是功能比较全面的容器环境管理系统,它不仅支持docker compose/k8s,甚至还支持docker swarm,不过目前还不支持containerd.
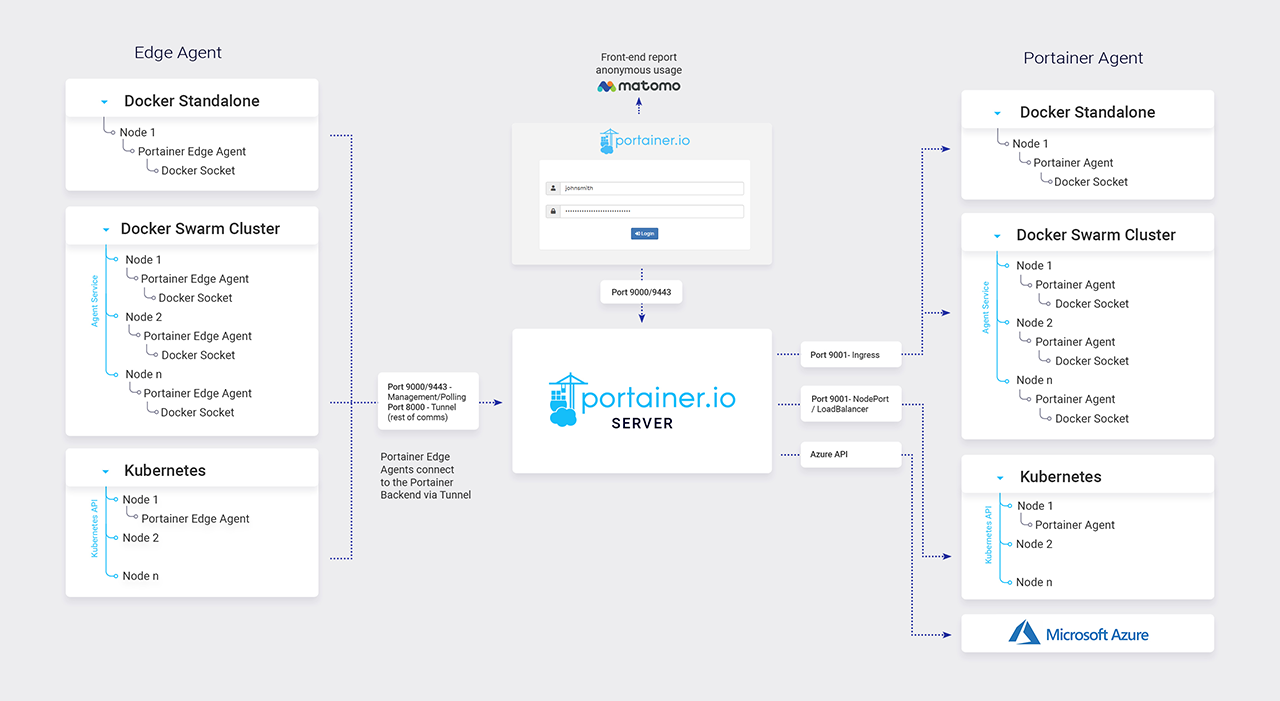
这个是它的架构图。左侧是边缘Agent,右侧是云端Agent. 该服务最开始的架构是pull模型,EdgeAgent在内网,只能改成push模型。
与想象的不同,该方案的Agent与Server是按需连接的。EdgeAgent会每隔几秒(默认是5秒)探测一下服务端是否需要建立长连接,需要的话才会建立websocket通道,所以Edge与Server的通信建立可能有一定的延迟。
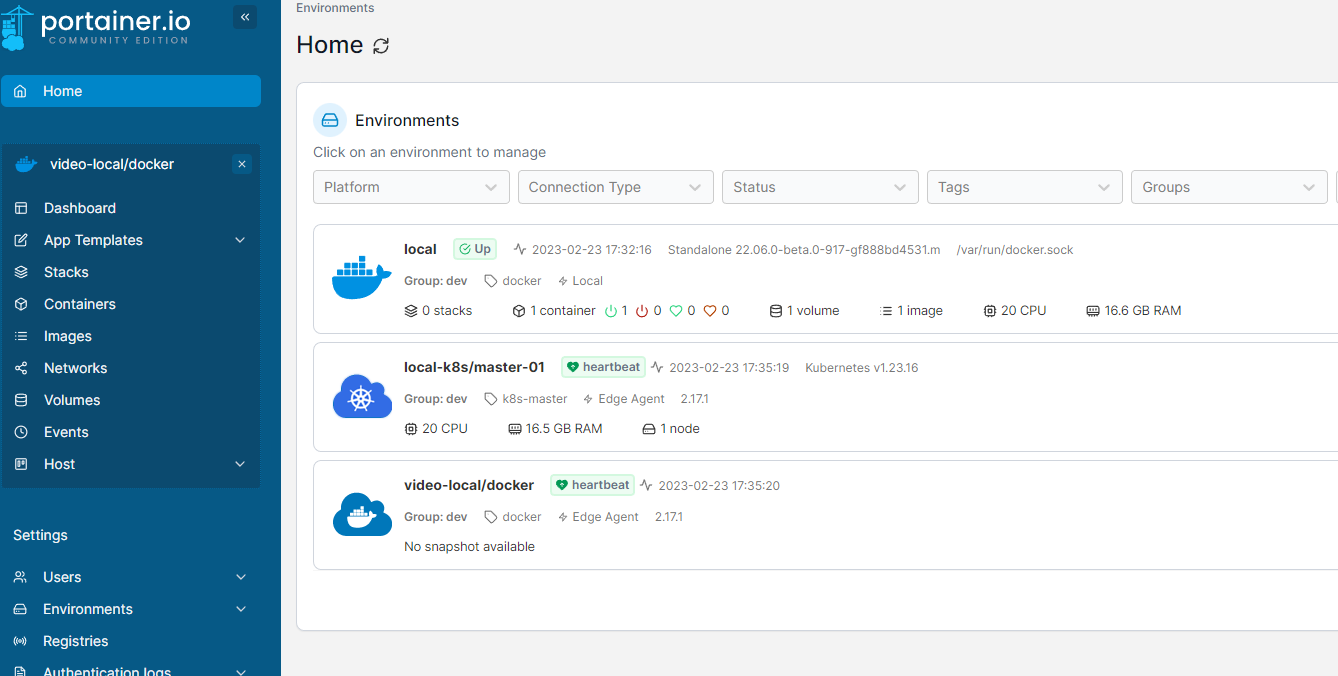
上面是该服务运行时截图。
经过测试,portainer可以比较完美的支持容器部署的常用功能,并能直接透传docker命令。k8s的支持稍弱,不过也能使用helm部署,和自定义API对象模板,足够满足一般使用需求。
对于应用部署,docker环境提供了简单的表单方案,当然支持直接上传compose file;k8s环境也支持通过表单简单部署ReplicaSets. 当然k8s环境可以使用其他部署方案,不一定要走他这一套,后面会详述。
有一定的权限隔离支持,但是不太完善(RBAC属于收费功能),可以通过前端封装API来解决相关问题。
总体来说,portainer配合docker和k3s集群,可以解决大部分应用部署的问题。需要注意的是,portainer的官方地址疑似被墙,安装脚本虽然完善,但是需要改动才能使用(当然k8s本身就被墙了……)。
k8s部署
这个可选的方案就很多了,目前在用的k3s+rancher也是比较成熟的方案,当然也可以用上面说的portainer+k3s替代。除此之外还有KubeEdge/OpenYurt等边缘计算的方案,下面对这些方案做一个简单对比。
k3s+rancher/portainer
前文已经说过这种架构,v1版本用rancher2.x配合k3s可以解决大部分k8s内部署的问题,k3s对k8s做了精简,并且自带了LocalPV和Ingress的配置,开箱即用。不过rancher没有官方的API指南,需要自行抓包看API,这点不如portainer; rancher的优势是用户更多,知名度更大,这样理论上会更加稳定一些。
这种架构最大的特点,是服务端并不需要k8s集群。这有利有弊,好处当然是比较轻量封闭;坏处是无法进行云边算力协同,边与边之间的集群也没有任何关系。如果是完全云原生化的服务,分区域部署,显然不能使用该方案。不过对于目前的墨斗平台而言,使用该方案无迁移成本,反而是最优选择。
另外值得一提的是,k3s部署非常简单,有官方的中国区镜像,整个过程可以在线完成,无须翻墙。
k8s+KubeEdge
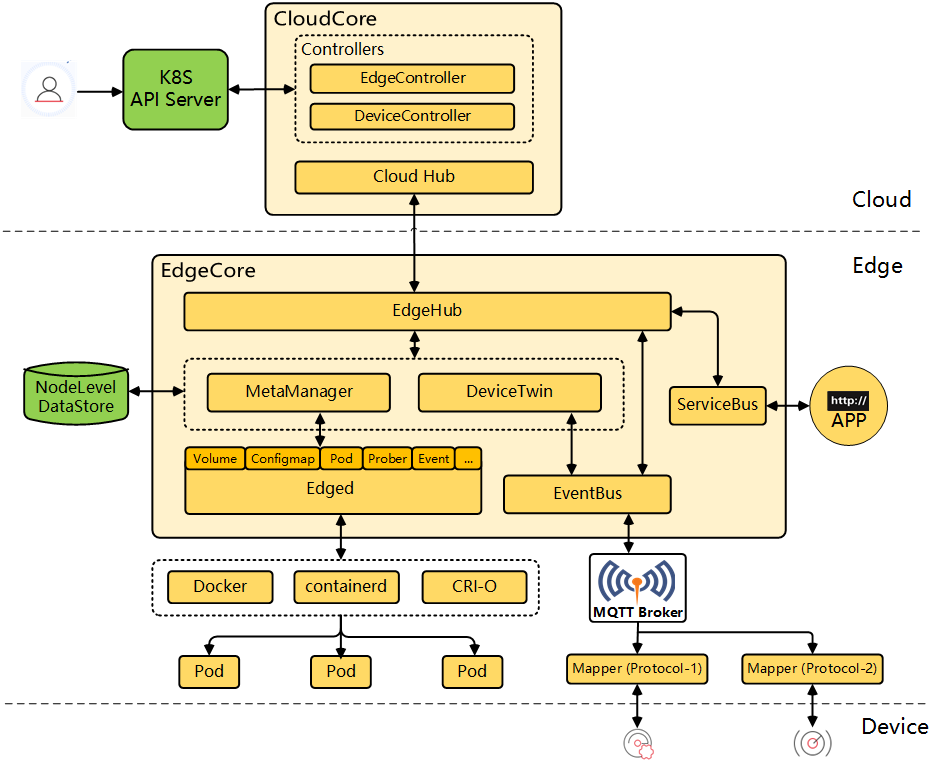
主要组件:
- 云端的cloudCore运行在k8s中,包括:
- CloudHub是一个websocket服务,负责与边缘端的EdgeHub通信;
- EdgeController,负责桥接k8s-apiserver与edgecore. 即所有在云端通过kubectl管理边缘端API对象的行为,都是通过它来转达的;这通过k8s apiserver的webhook功能实现;
- DeviceController. Device在KubeEdge中被定义为一种CRD. 所以也可以通过
kubectl来进行管理。这种设计实际上是将业务耦合进基础设施中,或者也可以说是完全云原生化;这种设计看起来很方便,但是实际使用中会有各种问题;
- 边缘端的EdgeCore是一套简化的k8s(与k8s生态不兼容,甚至无法运行kubectl命令);主要包括:
- EdgeHub,与CloudHub对应的websocket客户端,负责与云端进行通信;所有其他边缘组件都通过它与云端进行通信;
- Edged,简化的kubelet,负责边缘端容器编排;
- MetaManager,类似ETCD的元数据管理(使用sqlite);
- DeviceTwin,设备孪生(或者设备影子);可以理解为一种缓存,用于同步设备状态;
- EventBus,一个mqtt消息总线,订阅mqtt broker的消息,并转发给edgehub,后者再同步给云端(反过来的路径也是成立的);
- ServiceBus,类似EventBus,一个http消息总线,负责与边缘端运行的http服务进行交互;可以解决需要反向拉取HTTP数据的场景;
- Mapper, 一种协议抽象方式。遵从kubeedge的物模型规范,可以将协议实现为一个小的golang app,该app一般作为一个deployment在k8s中进行部署;
可以看出,kubeEdge是一个边缘计算的**打包(ALL-IN-ONE)**方案,主要解决了几个问题:
- 容器远程管理。可以在云端直接部署边缘端的服务,通过nodeAffinity等方式将服务部署到合适的边缘端;可以在云端统一管理边缘容器,不过在应用部署这块,kubeEdge并没有提供更进一步的抽象,该项目主要还是在IoT侧发力;
- 统一消息路由。应用层不需要关心消息如何传递的,云端服务只需和cloudHub通信,边缘端Mapper只需和Mqtt broker通信;
- 统一设备抽象。提供了统一的物模型设计,统一的驱动(协议)开发方式;包括统一的设备孪生设计,用于同步设备状态;
- 优化资源占用和满足离线自治。这也是其他方案都有的能力;
存在的问题:
- 统一设备抽象并不好。按着目前的设计,大量数据会被存储在云端etcd里(因为每个设备相当于是一个configMap),对于超大规模物联网平台而言,这个数据量会非常大。etcd搞增删改查的性能堪忧;
- 统一消息路由问题同样很大。首先是云端直连场景实际上并没有考虑,然后客户端的场景也只考虑了HTTP,实际上协议支持非常不完善。然后就是性能问题,目前这套设计消息会经过多个实体,最终才能到达云端服务,延迟必然收到影响。且在边缘端连接大量设备时,消息总线能支持多大的量还是未知;
- 目前仅支持golang mapper,这对使用其他语言技术栈的公司很不友好;
- 开发门槛提高。由于业务深入耦合k8s,完全云原生化,这就要求相关开发必须深入理解k8s的原理,不然出了问题很难调试;
- 文档稀烂,资料较少;虽然是华为主导开发,但是中文文档写的还不如k3s,英文文档版本也无法跟得上release, 出现问题比较难找到资料;
- 边缘端与k8s生态不兼容;只有少量开源项目支持kubeEdge,如kubesphere. 一般开源软件只兼容原生k8s. 边缘端实际上无法自治,在离线情况下,边缘端由于缺少kubectl工具,很多功能无法使用,比如离线部署应用;
经过实际调研,使用KubeEdge的用户大部分还是只用它最基础的容器远程管理和部分网络功能,IoT部分还是各自自研。实际上github上Mapper项目的star数还不足100…
k8s+OpenYurt方案
KubeEdge的问题实际上是过度设计了,如果只需要保留最基本的网络拓扑和容器管理功能,可以考虑使用OpenYurt.
这个方案和KubeEdge实际上不太一样,它主要解决的其实是跨机房集群问题,比如多个异地机房组成服务集群这种场景,所以在设备管理、以及轻量化这两方面,做的不如kubeEdge.

上图是OpenYurt的架构。包括以下通用组件:
- YurtHub:同样是流量代理,sidecar模式,同时支持云端和边缘端两种运行模式;
- Raven:打通云端和边缘端的网络流量,可以理解成一个VPN;
云端额外有YurtControllerManager和YurtAppManager,负责证书、调度等工作,用户一般无需关心;
边缘端额外有Pool-Coordinator,负责心跳管理,边缘端运维监控等功能。
OpenYurt主要是抽象了节点池的概念,我们可以简单的把一个边缘机房里的所有服务器理解为一个节点池。OpenYurt主要是方便云端统一管理各个节点池的资源,统一进行部署运维等工作;并能协调边云资源,解决负载不均衡造成的资源浪费问题。
优点:
- 与业务没有耦合,解决问题比较单一,比较容易理解;
- 为应用部署做了节点池等抽象,有比较完整的部署模型。这点KubeEdge没有;
- 中文文档完整,边缘部署比较方便(基本无须翻墙),云端部署缺乏一键脚本;
- 阿里云有个商业版本的Edge@Ack,两者设计几乎一致;
- 与k8s生态兼容(无论边云,本质上都还是k8s);
缺点:
- 成熟度不如kubeEdge,目前案例较少;
- 大规模使用的性能未知,官方暂未给出相关数据(仅有100节点的测试报告);kubeEdge有10w边缘节点的数据(但是没有多设备压测的数据);
- 相比于k3s,相关资料也不太多;
总结
虽然还有superEdge等开源产品,不过成熟度不够高,这里不再赘述。
不管哪个方案,都应该有一个宿主机管理工具(除非宿主机被映射到了公网,可以直接ssh连接),这里假设用nps(因为nps支持API控制,其他的不支持);
不管哪个方案,都应该有一套监控工具。这里仍然统一使用之前提的ElasticAgent + Elastic APM方案即可,支持所有环境(k8s/非k8s)的可观测性数据收集。当然,如果要集成到墨斗上,需要自己开发API与es进行交互,否则就直接通过kibana看就行;
方案1:同时支持docker/k8s,那么用portainer+docker+k3s,可以解决所有问题;我方服务主要和bore/portainer交互;
方案2:仅支持k8s,使用云端k8s+边缘OpenYurt/KubeEdge,其中kubeEdge仅使用边云打通功能,不使用iot相关功能;云端单独部署k8s master节点与edge通信,墨斗iot仍然部署在阿里云的托管集群里;我方服务直接和云端的k8s apiserver交互;
方案3:综合上面两个方案,使用portainer+OpenYurt/KubeEdge;
激进方案:使用KubeEdge的全部功能,重构墨斗平台,使其云原生化(工具量非常大,网关层的所有协议,hermes的设备管理,以及视频云信令服务都要重构,且都需要使用go语言)。需要将云端墨斗移入单独的k8s环境,与边缘端打通。当然,如果需要完全云原生化,还可以进一步的,抛弃springCloud框架,使用dapr/istio等云原生方案;
应用交付方案
k8s对大部分开发人员来说过于复杂,直接填写yaml的方式经常容易出错。因此如何进一步简化部署难度,减轻开发人员压力,也是一个值得讨论的话题。

上图是CNCF定义的应用交付模型:
- Helm 就是位于整个应用管理体系的最上面,也就是第 1 层,还有 Kustomize 等各种 YAML 管理工具,CNAB 等打包工具,它们都对应在第 1.5 层;
- 然后有 Tekton、Flagger 、Kepton 等应用交付项目,包括发布部署的流程,配置管理等,目前比较流行的是基于 GitOps 的管理,通过 git 作为“the source of truth”,一切都面向终态、透明化的管理,也方便对接,对应在第 2 层;
- 而 Operator 以及 K8s 的各种工作负载组件(Deployment、StatefulSet 等),具体来说就像某个实例挂了这些组件自动拉起来一个弥补上原来所需要三个的实例数,包括一些自愈、扩缩容等能力,对应在第 3 层;
- 最后一层则是平台层,包括了所有底层的核心功能,负责对工作负载的容器进行管理、封装基础设施能力、对各种不同的工作负载对接底层基础设施提供 API 等。
对于非云资源而言,一般使用Helm交付就能避免和底层k8s API打交道了,不过这里还有更好的选择。
OAM模型
OAM(Open Application Model)是阿里巴巴和微软共同开源的云原生应用规范模型,使用该模型可以分清开发和运维的责任,减轻开发使用k8s的难度。
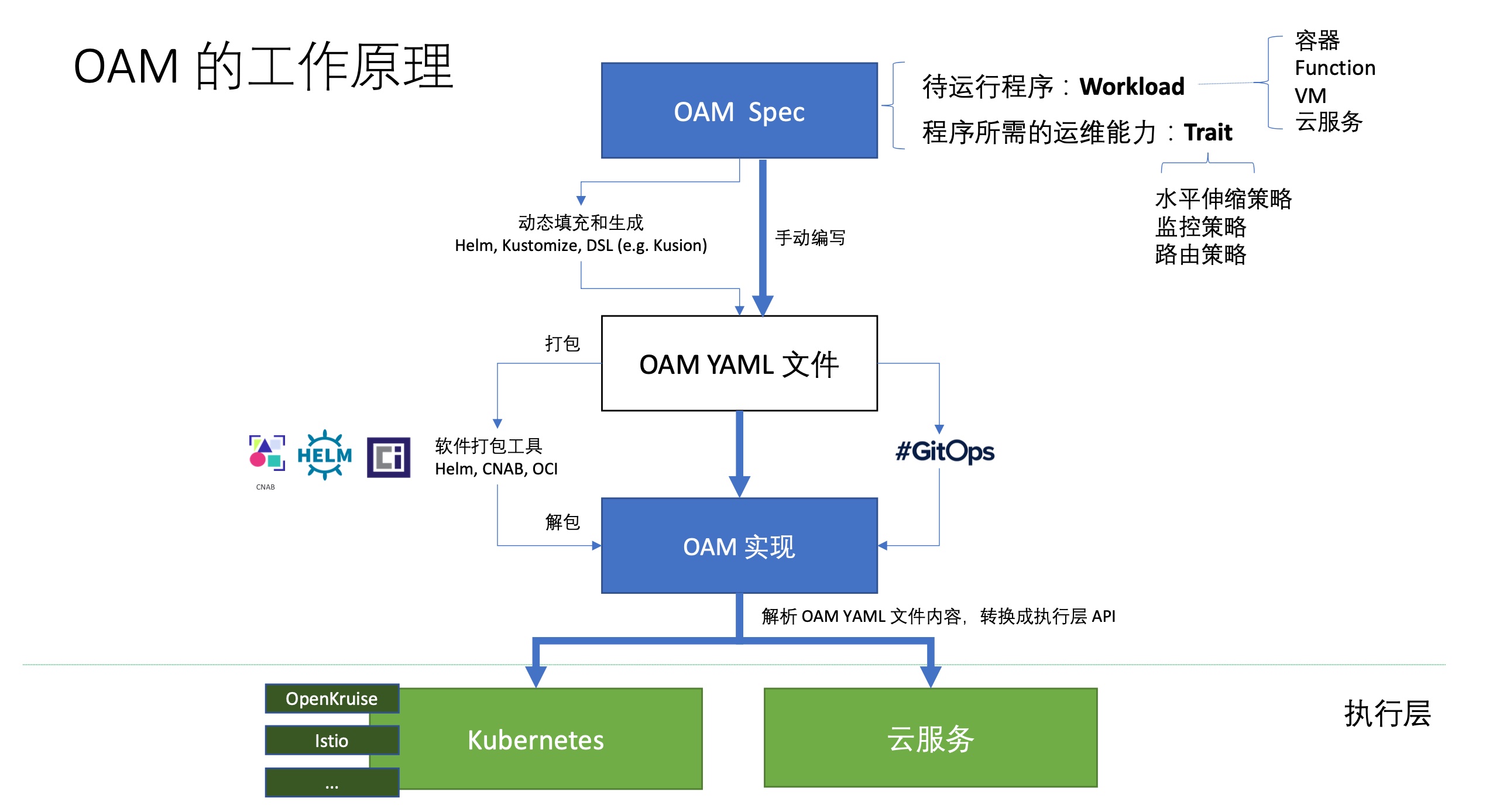
上图是其工具原理,可以看到实际上是在k8s前面又加了一层。
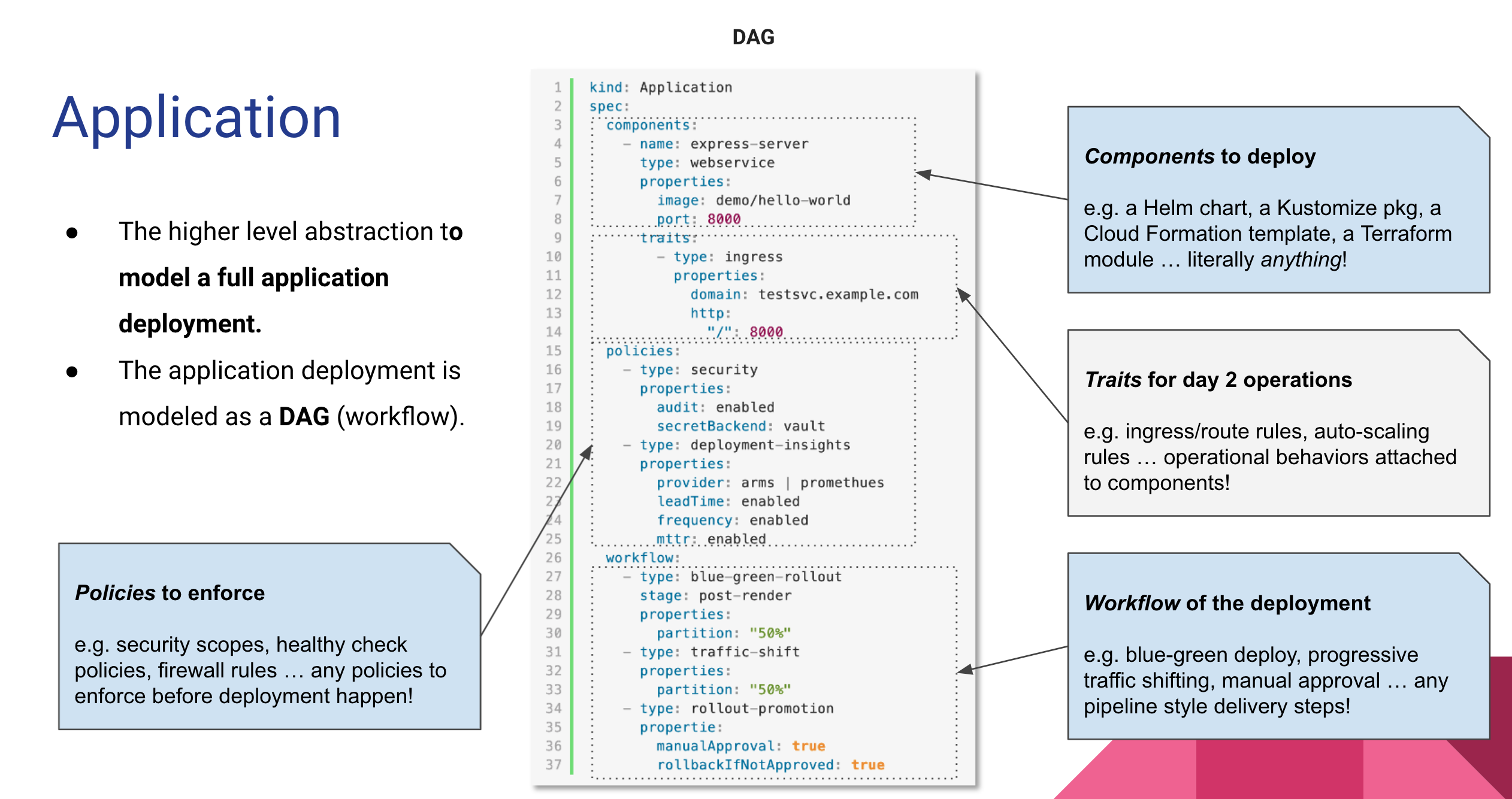
上图是OAM yaml的示例,可以看到它是一种CRD,抽象了Application这种资源,并指定了组件、运维能力、部署策略和工作流这四个部分组成一个部署计划。
kubeVela项目是OAM yaml的解析器,结合kubeVela项目和OpenYurt项目,可以比较好的解决应用部署/应用市场的实现难度。
kubeVela将用户明确分为运维方(平台团队)和开发者(使用者),前者负责维护基础设施,后者只需要在前者提供模板的基础上填入参数即可完成部署。并且可以在部署流程中增加人工审核等步骤,使工作流更加正规化。
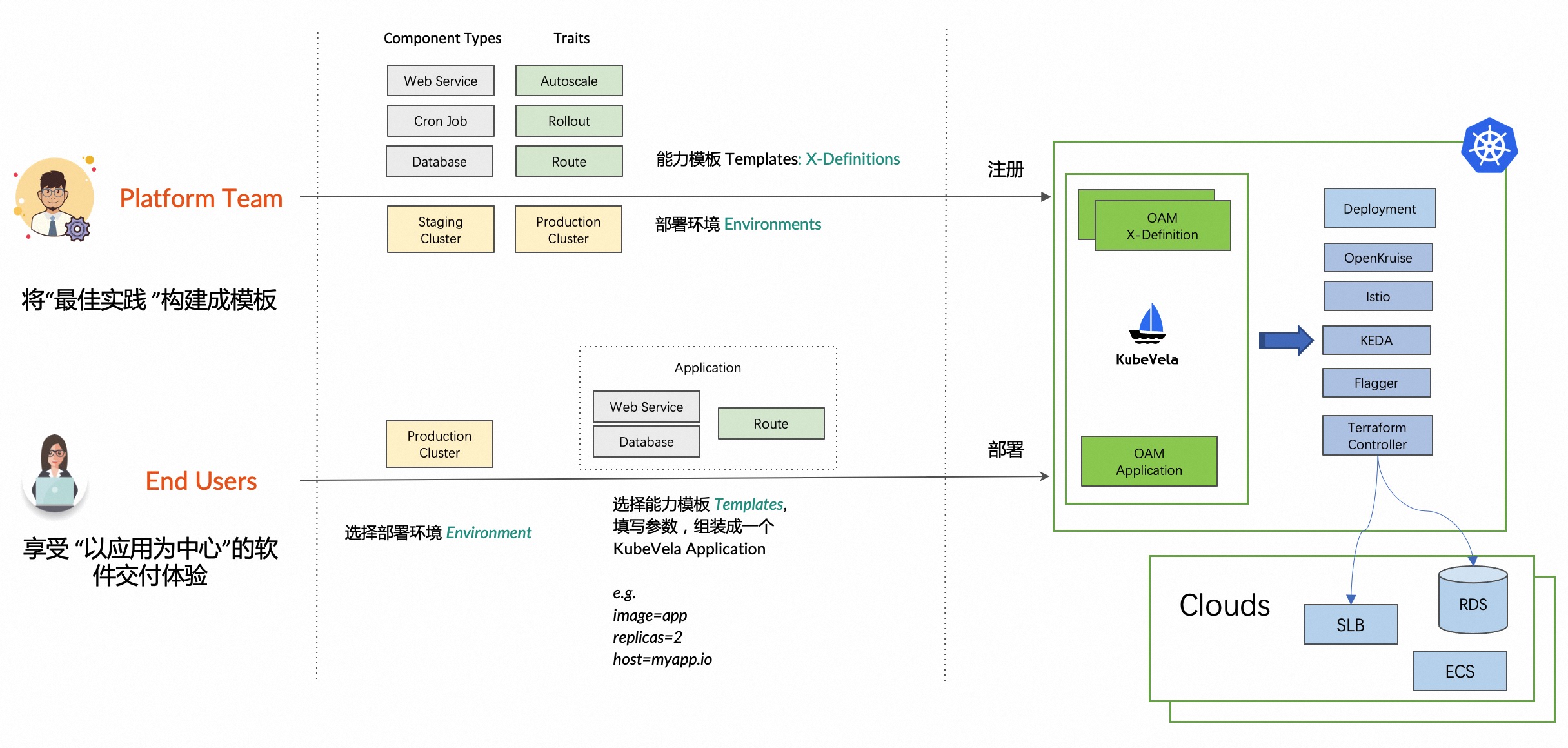
当然,kubeVela本身也比较复杂,增加了许多概念需要理解。
与OpenYurt结合使用的具体案例可以参考这里,有一些介绍。当然,由于kubeEdge的边缘端并不兼容k8s生态,这个方案理论上是无法在kubeEdge上跑的。
大规模部署方案
当智慧工地、智慧水务等产品已经成型,现场部署时再采用从手工安装OS开始,人工运行脚本安装的方式来安装基础设施效率就太低了。这时候最合适的是直接定制操作系统镜像,通过网络(PXE)全自动化安装、运行,全程无须人工干扰。
镜像制作可以参考Maas/foreman/uyuni/DRP等项目,下面是Maas的功能介绍(不过这玩意儿只有部署ubuntu server是免费的):
这里已经牵涉到IaaS领域,由于太过底层,这里不再赘述。
关于虚拟化领域有兴趣的可以查看以下词汇相关的资料:
KVM:Linux内核态的虚拟化组件。QEMU:Linux用户态的虚拟化组件。QEMU跟KVM结合提供完整的虚拟化技术支撑,属于架构的最底层。Libvirt:介于架构底层和架构上层之间,它将底层的虚拟化特性抽象成统一的API(应用程序编程接口),从而提供给上层调用。Packer和Vagrant:虚拟化客户端工具,它们属于架构的最上层,直接跟终端用户交互。同时,在客户端之间也会产生相应联系,我们将Packer的输出物作为Vagrant的输入源。
方案落地流程
从理论上来说,应用托管在做的是一个私有云,或者说混合云方案,工作量非常之大。因此最优先的实现是直接使用商用的产品,比如阿里云的Ack@Edge;其次应考虑在商业级平台基础上继续开发,如Red Hat OpenShift;最后才应考虑在上述开源平台的基础上从bare metal开始自研。
综合前面的讨论,可以确定自研的流程如下:
在第一个阶段,需要实现node级别的管理,即远程管理服务器的能力。该能力主要是给我们维护边缘服务器使用的,一般不应该开放给用户,该阶段相当于实现阿里云ECS的控制台(当然ECS和物理机之间还有一层虚拟机,比如OpenStack,这个我们当然不做)。如果有无法容器化的传统应用,可以考虑提供申请临时SSH/RDP权限的功能。
在第二个阶段,需考虑实现container级别的管理。提供镜像仓库供用户上传镜像,提供应用表单生成Dockerfile,提供用户直接提交docker-compose并部署的能力;提供用户直接与docker api进行交互的能力;注意docker本身并不提供任何权限相关的设计,也没有namespace的隔离。因此这里需要利用portainer等平台自带的权限相关功能来实现。或者直接跳过该阶段,到第三个阶段,因为第一个阶段实际上也可以完成该级别的能力。
在第三个阶段,需实现k8s级别的应用部署功能。初期可以粗放式允许用户自己完成应用部署,将边缘机器按节点池分类(参考OpenYurt)。用户可以通过填写表单提交deployment,或者通过提交yaml部署StatefulSet,或者提交helm chart。可以跳过该阶段,直接到第四个阶段;
在第四个阶段,可以考虑集成KubeVela这种精细化部署方案,用户层只需提交Application对应的表单,基础设施由我方编写模板进行维护,用户不再接触k8s底层,缩小用户权限;提供应用市场,供用户一键部署各种开源组件。
在第1~3个阶段之间,可以并行完成监控功能的集成。监控功能对内直接使用kibana,对外依次提供应用Log/Metric/Trace展示或者推送给第三方的能力,这三种数据的优先级依次降低;根据需求提供告警能力,或者让用户自己实现;看板能力理论上无须对外提供。kubeVela等项目也单独提供了监控的能力,也可以考虑直接使用。
在第四个阶段之后,平台需要进一步自动化运维管理,这时候再考虑大规模部署方案章节提到的各种相关技术。
在落地过程中,平台后端应当从hermes中剥离出来作为单独的微服务,前端也可以考虑独立出来做一个单独的平台(同墨斗的账号体系一致)。目前的应用托管v1, 实际上跳过了第一和第二个阶段,直接到第三个阶段,而且把常用的中间件对应的yaml直接预置到数据库中了,这只能是一个临时方案。
同墨斗其他功能保持一致,应用托管的所有功能应允许通过API来使用,所以需要梳理一下功能点和权限设计。
由于k8s生态非常活跃,各类产品的发布周期较短,因此无论是开发还是持续维护该平台都需要耗费较大的精力。不同于一般的业务开发,开发该平台需要大量的运维领域知识,因此整体时间预期会比较漫长。