监控平台调研报告
广义的监控又称为Application Performance Monitoring(APM),即应用性能监控。其数据类型主要包括:指标数据(Metrics),日志文本(Logs),分布式追踪(Traces),这又称为可观测性三支柱。

其中,Metric是监控系统的核心,其又可以细分为os/container/service/middleware的Metric,实现方式一般是周期性采样,并进行计算聚合;
Trace一般用于调试和定位问题。Trace的重要性要稍微差一点,一方面可以通过Log实现简单的Trace,另一方面它会对应用的性能造成一定的影响。如果可以重放用户的请求,用Arthas这种线上诊断工具代替也勉强可以;
Log则比较零散,可以包括各种信息,比如用来提取Metric,以及记录各种Event. 此外,客户端埋点上报的数据一般是用来统计用户行为的,也可以视为一种Log;
服务质量的量化数据,一般简称SLI(Service Level Indicator);而开发/运维人员对于系统稳定性的需求目标,一般称为SLO(Service Level Object)。对于某个服务监控体系而言,最重要的就是确定承诺的SLO,告警和统计都是基于SLO来制定的,即所谓面向SLO的监控平台。
四个黄金指标
所有的监控都是为了更好的用户服务质量,Google总结了所谓的Four Golden Signals,是监控系统各种Metric的重中之重:
- 延迟:服务请求所需时间。重点是区分失败的请求和成功的请求,需要记录端到端的整体延迟,也要记录每一次IO调用造成的局部延迟;
- 吞吐量:系统当前流量,用于资源估算。例如HTTP请求的QPS,或者音视频请求的bps;
- 错误:各种错误,如HTTP 500,或者rpc报错等;一般关注错误的类型和错误发生的速率;
- 饱和度:各种受限资源,如CPU、网络、IO、内存、磁盘的使用率;
一般而言,服务的SLO都是围绕这四个黄金指标来制定的。
监控平台选型
最核心的Metric平台,随着技术的发展,主要从200x年的zabbix all-in-one体系,逐渐进化到Google主导的云原生体系下的exporter(采集)+prometheus(存储)+alertmanager(告警)+grafana(展示)。后者解耦了监控的各个流程,但是也增加了监控系统的复杂度和轮子数量,由于MySQL、Redis等各种中间件的二进制exporter都需要单独部署,所以实际操作起来比较繁琐复杂。
Log方面,除了EFK(filebeat+elasticsearch+kibana)的经典体系,也还有loki/splunk等可选;zabbix支持简单的日志统计功能,如果需求不高,也可以用google的mtail组件转换成prometheus的exporter;
Trace一般认为起源于Google的Dapper,但是这个没开源。目前主流是CNCF主导的OpenTelemetry体系,兼容的开源实现包括Elastic APM/Jaeger/SigNoz 等;
此外,由于我们使用了阿里云平台的商业组件,因此还要整合阿里云提供的监控数据;阿里云有对应Metric的openAPI;
虽然Google提倡监控平台各个组件解耦独立化,但是考虑到人力成本,我们更倾向于使用类似zabbix这种all-in-one的监控平台以减少我们的工作量。当然zabbix确实太古老了,虽然6.x也尝试支持云原生体系,但是用起来还是很不方便,其内置的表达式体系也不如PromQL这么现代化,学习成本很高。目前视频云已有的一套zabbix系统也仅适合ECS服务使用。
经过调研,一体化的集成平台主要包括:
- OpenTelemetry,CNCF主导,几乎必然是未来的标准。Trace方面比较成熟,多语言支持完善,可以考虑使用其客户端SDK/Agent接入兼容其标准的后端,Metric和Log大多还处于experiment状态。Metric规范会兼容OpenMetric,而后者则几乎100%兼容Prometheus的Metric规范。官方推荐使用prometheus作为Metric后端,Jaeger作为Trace后端;Log相关规范暂时还没有定下来;
- Apache SkyWalking,国内个人开源(但是并没有中文文档),现在是Apache顶级项目。老本行是tracing,9.x已经支持Metrics/Logs收集(支持filebeat作为采集端)。Trace做的比较完善,java服务可以通过修改字节码完成无侵入式的追踪,其他语言支持一般;支持metric拉取,但是做的比较简单,通过修改静态配置文件完成;Alert功能也有,支持动态配置(可以集成nacos);Log方面就是支持Filebeat传输,可以在trace时定位到上下文的log,方便调试问题;虽然号称兼容OpenTelemetry,但是官方文档中没看到;
- 夜莺(Nightingale)平台,滴滴开源,有对应的商业平台。主打metrics,可以看做prometheus的商业版,集成了grafana和alertManager,并且有自己的
Categraf采集器,未涉及Trace和Log相关采集。夜莺的商业版倒是支持all-in-one,不过需要购买。 - Elastic Observability, ES关于可观测性推出的一体式方案。Filebeat的Log收集是老本行,通过MetricBeat收集Metric,并支持Elastic APM作为trace(兼容OpenTelemetry),并且支持JavaScript的Agent可以拿来做用户行为跟踪。使用kibana做看板,告警支持完善,整体成熟度比较高。
我们可以考虑使用夜莺+Jaeger+EFK,或者夜莺+Skywalking,或者考虑直接用Elastic的all-in-one方案。考虑到OpenTelemetry必然是未来的规范,以及我们的多语言环境,可以考虑排除skywalking。
公司已有组件
Metric:一般用prometheus配合discovery抓取,目前院内无部署;
Logs: Plain Log目前统一使用filebeat抽取到es里,配合kibana使用,但是目前仅保留7天;结构化的JSON日志,目前各应用还未使用,需要进行应用改造;
Traces:院内目前在k8s里布置了一套skywalking;
架构设计
夜莺+Jaeger+EFK
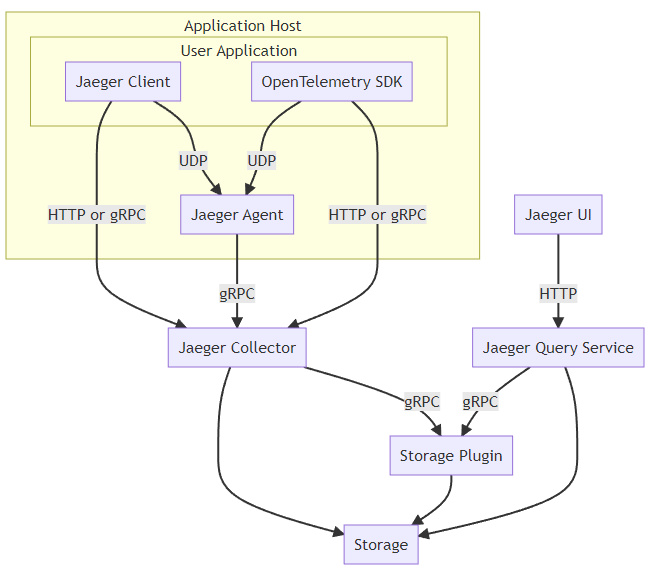
这是jaeger的架构,目前推荐使用OpenTelemetry的SDK。只有Trace功能,也是push模型。

这个是夜莺的架构图,它主要是代替Prometheus+AlertManager+Grafana,所以主要是pull模型,不过也支持Telegraf这种push模型。
由于我们部分服务在k8s外面,所以push模型的server最好部署在k8s外(在k8s里面要开NodePort暴露到ECS内网),pull模型的则必须部署在k8s里。

上图是IoT目前的服务生态,这里给出一种可能的架构:
- prometheus或者说Nightingale部署在k8s里:
- 自建的中间件通过agent(这里写的是categraf,用别的也可以)转为exporter,其中部署在k8s中的(主要是redis),需要通过sidecar模式部署;
- 中间件如果支持水平扩容,也需要考虑discovery方案;
- 购买的阿里云商业中间件,需要通过阿里云的API进行Metric采集;
- 自建的服务目前都注册在nacos中,通过nacos的discovery获取ip,完成采集;
- jaeger部署在物理机上(或者k8s暴露NodePort):
- 由客户端生成TraceId,或者网关层(如Nginx)注入TraceId;
- 请求在服务和MQ中流转,需要显式修改代码带上TraceId,当然可以通过AOP或者抽象成库等方式减少工作量;
- 使用OpenTelemetry的sdk显式push trace,java服务可以无侵入;Go/C++服务必须修改代码,都有一些性能影响;
- 使用EFK传递结构化日志;
- 从日志中提取出Metric,例如组件延迟,请求错误率等因子,export给prometheus;
- 边缘端通过agent push:
- 边缘端环境比较复杂,而且无法应用pull模型,只能通过agent收集之后push到prometheus pushgateway上;
- 边缘端可能需要自行开发一个统一的agent进行上报;
- 边缘端还有一些windows场景,虽然已经逐渐废弃,支持力度需要考虑;
- 通过AlertManager或者其他服务告警:
- 错误和延迟相关的告警,可以通过TraceId来消除部分重复告警;
- 饱和率和吞吐量相关的告警,应尽量自愈;
- 错误需要细分,代码bug导致的异常抛出应当立即告警,服务间通信超时这种则一般通过百分位设定阈值;
- 理想情况下,可以通过点击告警中的TraceId跳转到对应Trace,并看到上下文日志(需要二次开发整合);
- 告警的设计本身需要仔细考量,一般使用promQL来做告警条件;
使用Elastic Observability
ES可观测性方案基于ES做了全链路可观测,集成度非常高。

Filebeat和Metricbeat都是push模型,所以类似zabbix,将ElasticSearch、kibana和Elastic APM部署在ECS上。在k8s集群/边缘侧部署MetricBeat作为采集器,将信息推送到ES即可。另外,值得一提的是MetricBeat支持windows事件日志采集。
考虑到人力成本,这里推荐使用Elastic Stack技术栈,下面按该技术栈进行分析。
告警自愈
Google在SRE中推荐大部分告警应当自动化处理,需要人工处理的case应尽量减少。
但是告警自愈本身是有一定风险性的,所以这套自动化系统本身也需要监控和测试。
服务回滚
当服务上线后短期内出现大量故障告警,且持续时间较长(考虑可用性SLO占比),应当考虑自动回滚机制。
但是自动回滚可能会比较复杂,例如涉及数据库结构的更改、客户端版本的撤回等等,所以还需要配合备份来使用。
一般不建议自动回滚,而是需要手动操作。
当然更理想的解决方案是通过灰度发布来缓慢上线,避免线上服务雪崩。
弹性扩容
如果饱和率和吞吐量到达阈值,弹性扩容是最简单的解决办法。
当然弹性也不能无限的弹,如果是bug导致的,最终会耗尽宿主机资源。k8s可以在HPA里设置min/max replicas控制pod的数量。
商业资源,如阿里云的SLB,弹性扩容比较困难,还是需要人工处理。
延迟的问题,如MQ的offset过大,一般也可以通过弹性扩容来解决。
弹性扩容整体需要依赖k8s的HPA机制,结合prometheus指定custom metrics,目前我们的k8s集群中是没有部署的,需要我们自行解决。并且,需要解决权限问题。
此外,扩容之外也要考虑缩容的需求,一般扩容比较激进,而缩容需要稍微谨慎一些。整体而言,需要在基本冗余的基础上,保证一定的资源饱和度。
服务降级
当自动扩容达到极限,仍然无法解决饱和率问题,就要考虑服务降级了。
服务降级只能从应用层面设计,暂时熔断非关键服务,如在接入层直接返回500,以此保证核心业务能正常work。甚至可以给客户端回复特殊状态码,让客户端自行限流,这样可以从根本减少接入层流量。
服务降级可以设计成一个简单的开关,也可以设计成多层降级,直至饱和率回到正常。总之这里需要业务层自己实现相关逻辑,并经过实测演练保证降级效果。
创建工单
各种bug导致的告警,肯定是无法自愈的,应当打通云效创建工单;
即使是自愈的case,理论上也要创建工单,记录下自动处理措施并抄送给服务相关人员;
需要人工接入的,必须创建事故单,记录下详细的处理流程以供后续参考,并可以根据处理步骤来考虑逐步自动化处理;
二次开发
主要考虑一下工作项:
- 告警自愈的webhook开发;
- 打通工单系统;
- 为阿里云PaaS组件撰写exporter;
应用改造
重试逻辑修正
一些常用的最佳实践:
- Retry需要指数避退+随机扰动,无论是RPC还是REST调用;
- 细分错误码,确定哪些错误需要retry,哪些不需要;不同的错误码对于制定SLO也大有裨益;
Fast-Fail
- 服务器时钟同步,在入口层注入时间戳;
- 在请求流转的过程中,首先判断用户层是否已经超时,如果是则应当放弃处理;
- 当然更理想的应当是将耗时请求异步化设计;
Trace适配
这个工作量较大,理论上在跨协程/线程/进程的流程中,需要手动加入TraceId/SpanId的流转。尤其是非Java类语言,需要改造的工作量不小。前端的用户行为跟踪主要针对墨斗平台,目前可以不考虑。
当然可以使用改造基础库的方法隐式注入,但是目前公司的基础库并未统一。组内基础库也没覆盖各种私有协议,总之还是要排查修改。
另外就是重要Trace建议通过JSON格式的日志记录,plain text只能通过正则处理,效率太低。
接口设计改造
泛用型接口,比如给设备发送命令的cmd/send,根据物模型的不同,实际上延迟差距非常大。
对于这种接口,一个思路是将cmd写到url里,即cmd/send/<CMD_XXX>,这样可以从网关层统计端到端延迟。
还有一种思路就是使用Trace/Log,显式记录不同cmd的延迟,并借此设计API的SLO.
配置文件
Google推荐使用Jsonnet这种封闭式语言生成配置文件,并将生成脚本放在代码仓库里,在编译时顺便生成配置文件。通过配合Json Schema,可以在编译时就检测配置文件的有效性,避免因为配置出现问题导致的线上bug。
灰度发布
目前没有灰度的实施流程,全链路灰度实施难度实际上比较大,需要与运维协商。
另外,灰度的Log、Metric与稳定版本需要区分开来,SLI的看板也要独立出来,这样才能迅速定位到版本的问题。
自动化测试
需要进一步完善自动化测试系统,这样通过测试环境的监控就可以尽可能解决各种错误。通过定期的压力测试,也可以保证告警自愈机制的可靠性。
IoT平台的SLO
SLO需要从用户使用体验出发,根据用户的需求来制定。不同服务的SLI需要仔细讨论后商定,这里只是举几个例子。
对于IoT平台而言,用户可见的SLI分为两类:对设备侧和对用户侧。
设备侧的数据可以分为以下几类:
- 周期性采集数据,如各种传感器。量大,关注实时性,允许丢失甚至故意丢失;此时主要SLI应当是端到端的延迟;
- 触发性数据,如用户经过闸机的考勤记录,量不大,但是关注一致性,不允许丢失(设备会有重试);此时主要SLI应当是数据的到达率;
- 流媒体数据,主要是各种音视频数据,量特别大,带宽消耗巨大,关注实时性,允许丢包;此时SLI就比较复杂,对于视频监控,理论上追求的是在带宽受限的情况下,用户观看到视频的及时性和画质满意度,这个SLI的计算方法就需要权衡;
设备侧的错误需要区分是本身的问题(比如上报数据没按协议来),还是服务的问题。由于设备使用各种私有二进制协议,因此在Trace跟踪这里相对麻烦。
用户侧就与一般的服务类似了,根据API的不同,一般追求端到端的延迟百分位,低错误率等。
高性能服务还要考虑饱和度与吞吐量之间的比例关系,这个适合作为内部SLO,无须对外。
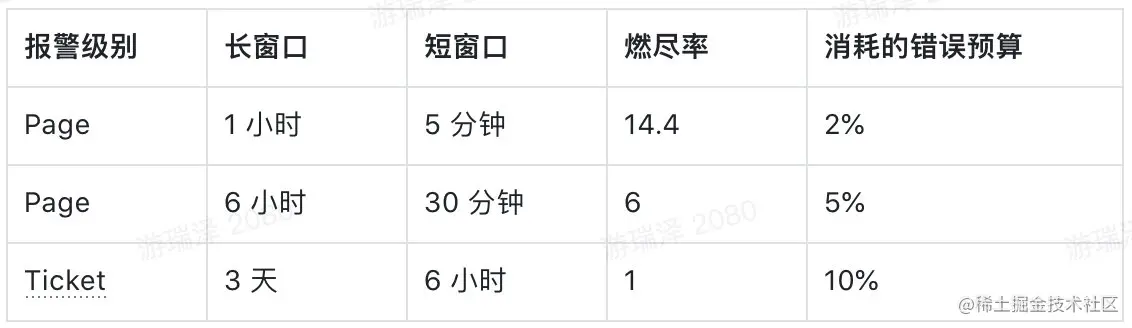
SLO需要一个时间窗口,根据业务性质的不同,也可以指定自然月,甚至季度作为时间窗口。Google推荐按4周的滚动周期作为时间窗口:比如最近4周hermes HTTP API的成功率(非5xx)在99.9%. 那么系统允许有0.1%的错误,这被称为错误预算。理想情况下,如果系统的流量均匀,那么每天的错误响应不高于0.1%,就不应该触发告警。但是实际情况往往非常复杂,Google推荐设置基于SLO的多个时间窗口、多个燃烧率阈值作为告警的条件,可以参考这里。
此外,告警需要区分等级,很多时候大问题是从小问题开始的,但是小问题不一定引起大问题。下面是99.9%SLO的推荐报警设置: